Posts
-
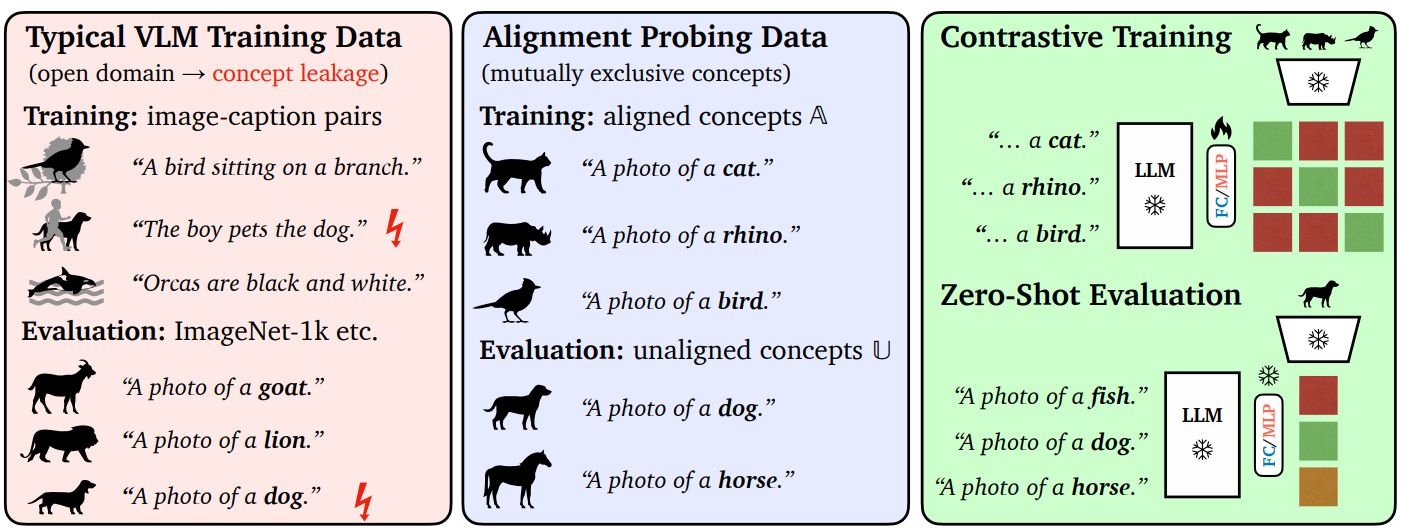
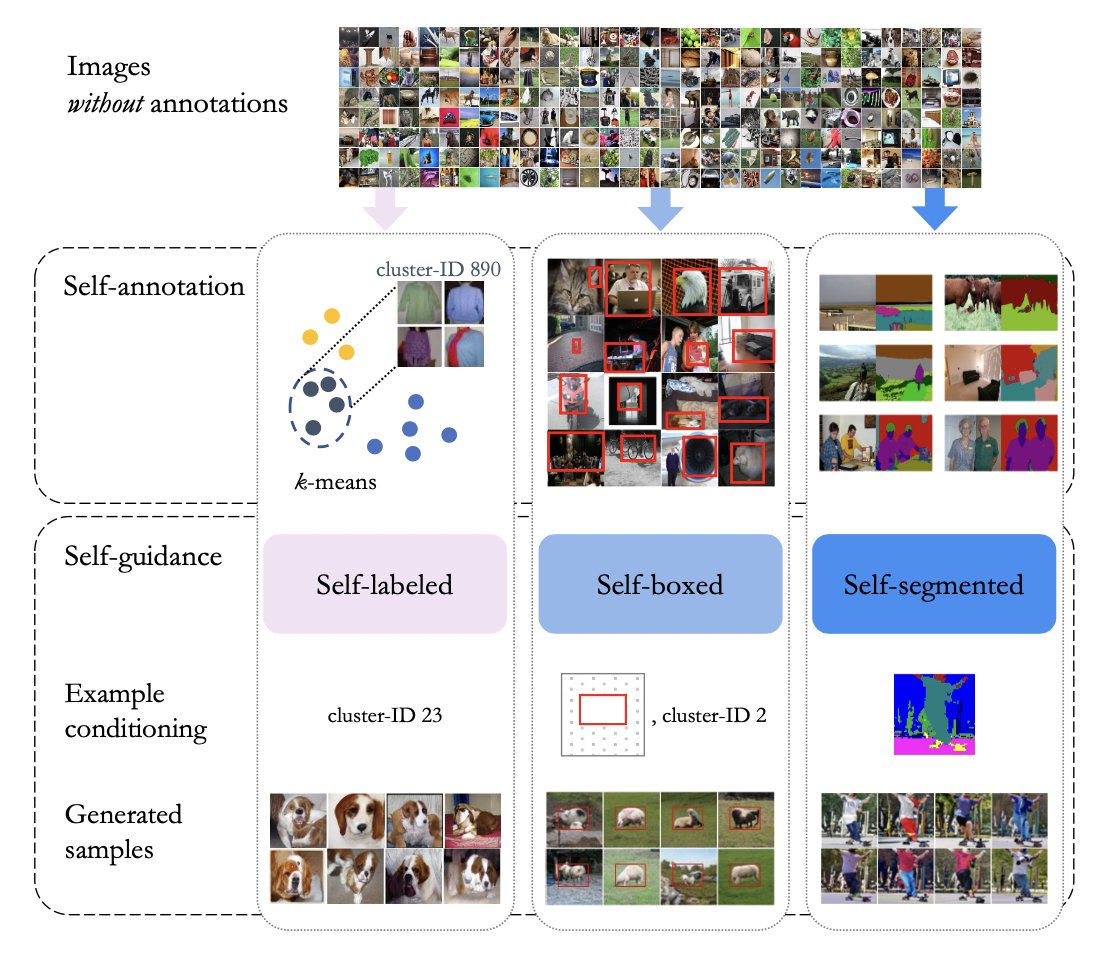
When Language Models Start to See
Can a language model help recognize images—even with only minimal visual training? Our recent research in Transactions on Machine Learning Research (TMLR journal) shows that it can.
Although modern language models are trained purely on text, that text richly describes the visual world: objects, scenes, and how things relate. The question explored in this work is whether such models already contain visual structure that can be quickly unlocked with a small amount of image data.
The answer is yes. By adding a lightweight vision–language alignment step, researchers show that stronger language models require far less image–text training to perform well on visual recognition tasks. As language models improve, their representations align more naturally with visual concepts, making the final learning step remarkably efficient.
The technological breakthrough is clear: instead of training massive vision–language systems from scratch, we can reuse powerful language models and adapt them to vision with minimal extra supervision.
This points toward more data-efficient, scalable AI systems—and a future where language provides a surprisingly strong foundation for visual understanding.
-
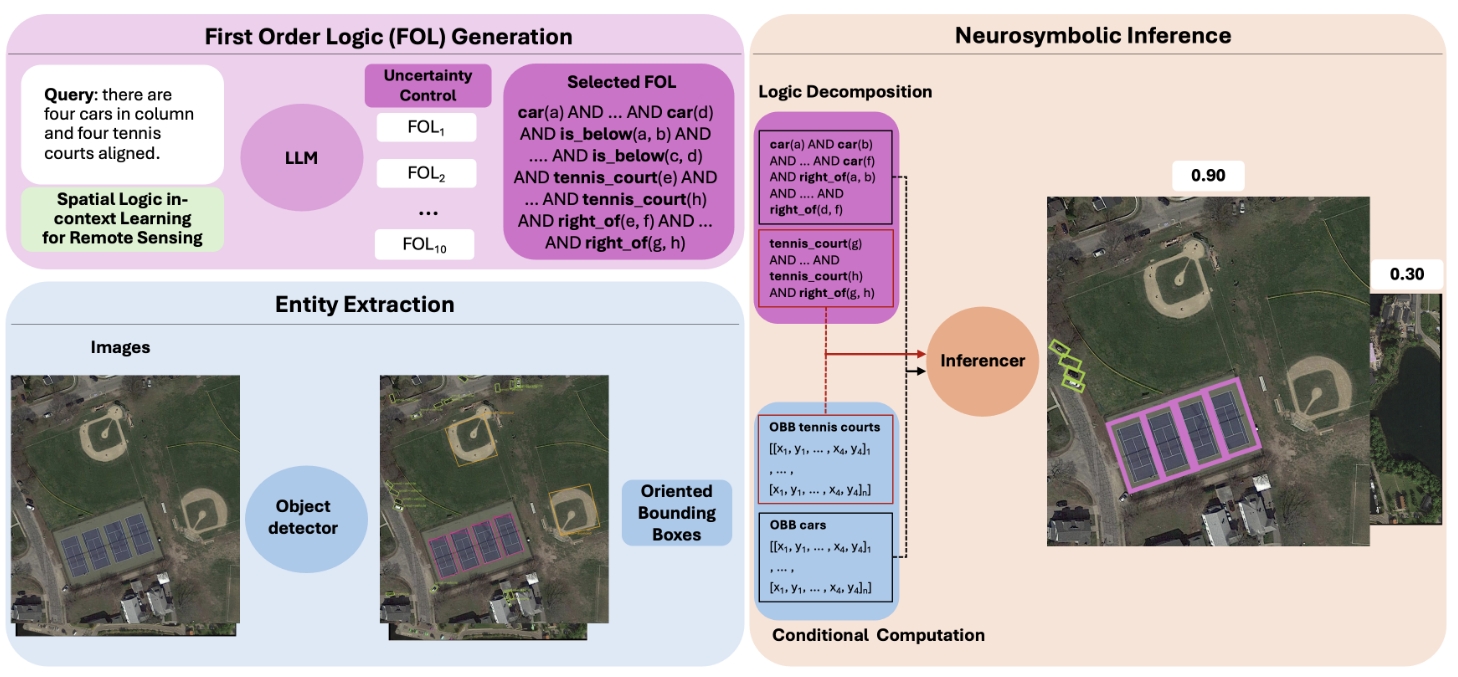
Seeing the Bigger Picture: How Logic Helps AI Understand Scenes
Our paper “Neurosymbolic Inference on Foundation Models for Remote Sensing Text-to-image Retrieval with Complex Queries” was accepted for publication in ACM Transactions on Spatial Algorithms and Systems.
The proposed method is about situation understanding. We reason within images, focusing on the relationships between objects. Relationships between objects are important for interpreting situations. For example: a van next to a boat, farther away from the highway, may indicate an illegal offloading.
We have found that modern multimodal AI models perform rather poorly when it comes to interpreting such relationships between objects—especially when the relationships become more complex and involve multiple entities; for example: A is close to B and C, while B and C are aligned one behind the other, and C is of the same type as D.
That is why we take a different approach: we use logic. With first-order logic (FOL), you can precisely define the relationships of interest. We interpret this logic through neurosymbolic AI, which we place on top of modern AI. This layer combines the information extracted from images about the objects with the logic describing the interesting relationships.
Here is the key part: the user asks questions to the system in natural language. This textual query is translated into FOL by an LLM that we have specialized using in-context learning. Each image can then be analyzed to determine whether a relational pattern matching the user’s query is present. You can see this in the following figure:
-
DINO v3 builds on our work!
DINO v3 has been released. And it builds on our recent ICLR 2025 paper!
Our method, NeCo, improved the DINO patch-level features by self-supervised post-training. We enforced that the patches in two views of the same image (i.e. different augmentations) follow the same ordering, relative to an external memory set of representative image patches. This ordering proves to be a very strong learning signal: it is much stronger than just looking at the nearest neighbors only, or looking at clusters of patches in embedding space.

Proud that it was cited by DINO v3!
-
Lecture on Foundation Models
Every week, a new large AI model is released by the big tech companies and research labs: CLIP, Flamingo, Grounding DINO, SAM-2, etc. They offer a big potential for us, across a broad range of capabilities. From image classification and retrieval (CLIP) to object detection (Grounding DINO), scene segmentation (SAM) and Visual Question Answering (e.g. GPT4o).
The question is how to use them optimally for the task at hand. One challenge is that today’s large AI models are trained on everyday web images with common objects (cars, skateboards, types of cats, etc.). Clients often want something different: other images (e.g. drones that have other viewpoints) and/or other objects. It requires some tricks to adopt large AI models for our capabilities, we call these adoption strategies.
We have identified four strategies: (1) include pre- or post-processing, e.g. to apply the model to pre-filtered image regions, or to check or clean-up the predictions afterwards. (2) change the model behavior from outside, by changing the textual prompt, or improve the question. (3) re-learn part of the model, by adding a few learnable elements (e.g. prompt tuning, LoRa), or finetuning all weights (e.g. few-shot learning). (4) change the model itself, i.e. its architecture, for example to modify the tokenizer which enables to learn without forgetting (e.g. Grounding DINO extension that it can learn new objects without forgetting known objects).
During this lecture, I have discussed these four strategies.

Course website.
-
Best Paper Award about Dynamic Prompting
We won the Best Industrial Paper Award at the International Conference on Computer Vision Theory and Applications!

Our model learns to adapt the textual embeddings to the image at hand. This demonstrated to be very useful for finegrained recognition, unlocking highly specialized features.
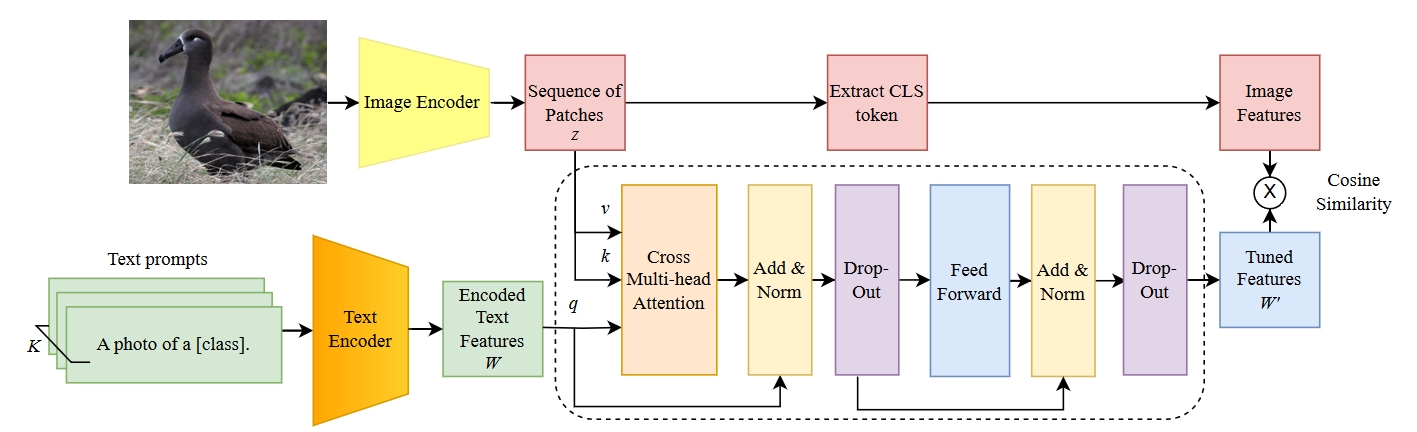
A collaboration with the Rijksuniversiteit Groningen (RUG). See Publications for the paper and more details.
-
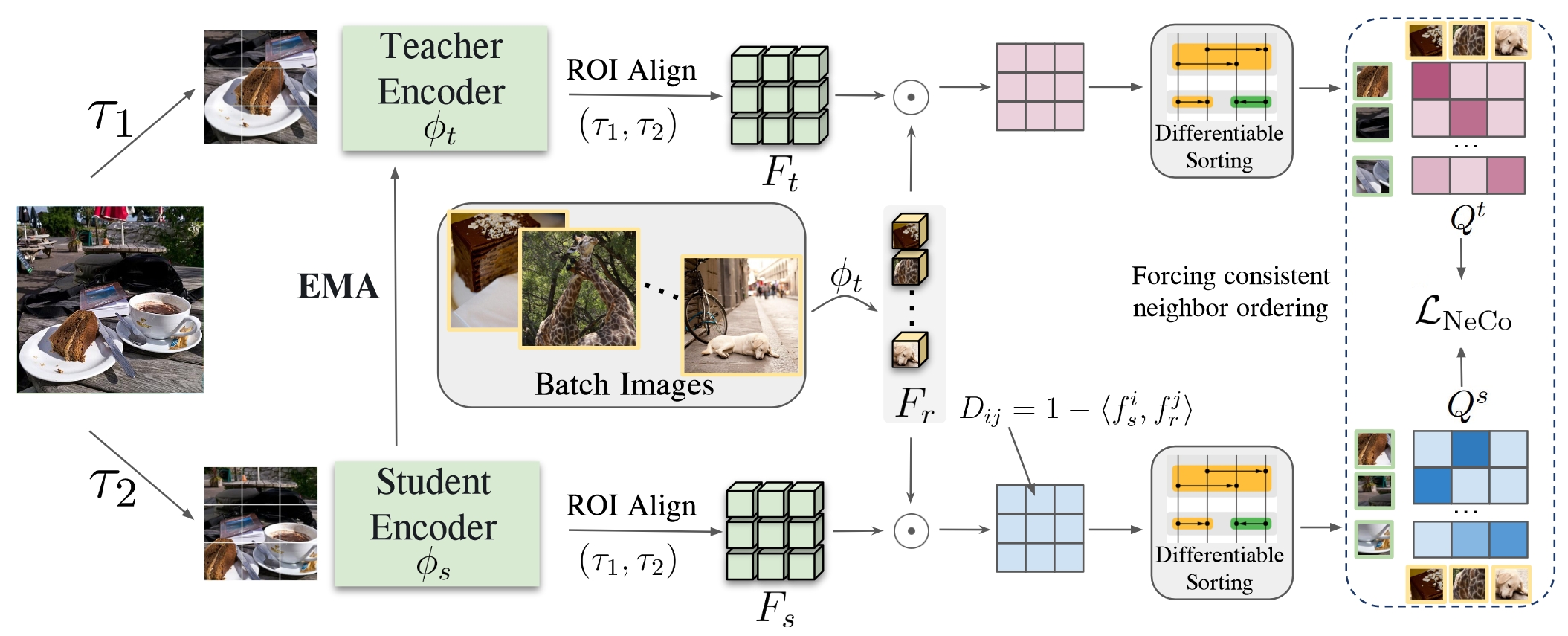
Improving DINO v2's Scene Understanding
DINO v2 extracts strong features from an image at the patch level. However, it is not very consistent across images, e.g. it does not yield the same features for the tip of a finger across various people in different images. We aimed to improve this, by a self-supervised learning strategy.
Our strategy aims to improve the consistency, by enforcing that the patches in two views of the same image (i.e. different augmentations) follow the same ordering. This ordering proves to be a very strong learning signal: it is much stronger than just looking at the nearest neighbors only, or looking at clusters of patches in embedding space. Compared to contrastive approaches that only yield binary learning signals, i.e. “attract” and “repel”, this approach benefits from the more fine-grained learning signal of sorting spatially dense features relative to reference patches.
We call our method NeCo: Patch Neighbor Consistency.
We establish several new state-of-the-art results such as +5.5 % and +6% for non-parametric in-context semantic segmentation on ADE20k and Pascal VOC, +7.2% and +5.7% for linear segmentation evaluations on COCO-Things and -Stuff and improvements in the 3D understanding of multi-view consistency on SPair-71k, by more than 10%.

Its features are much more consistent across images and categories. E.g., it yields the same features for the tip of a finger across various people in different images.

Accepted at International Conference on Learning Representations (ICLR) 2025. See publications.
-
Cycle Consistency for Multi-Camera Matching
Matching objects across partially overlapping camera views is crucial in multi-camera systems and requires a view-invariant feature extraction network. But labelling in several cameras is labor-intensive. We rely on self-supervision, by making cycles of matches, from one camera to the next and back again. The cycles can be constructed in many ways. We diversify the training signal by varying the cycles.
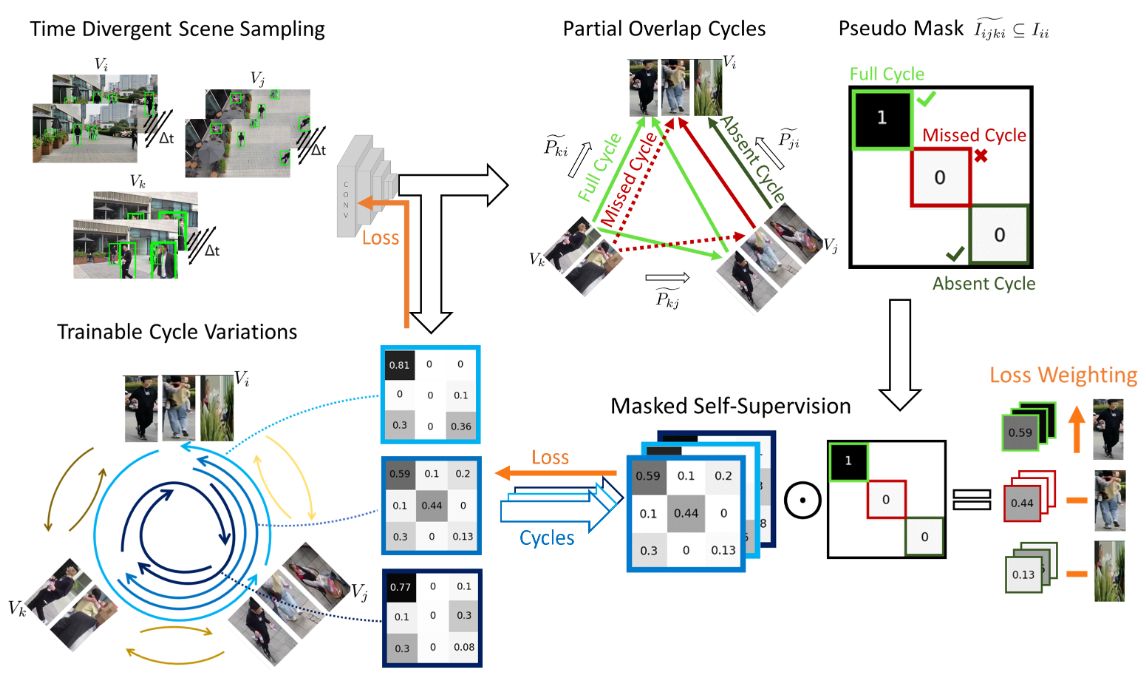
We achieve a 4.3 percentage point higher F1 score. Especially when there is limited overlap in camera views, the matching is improved.
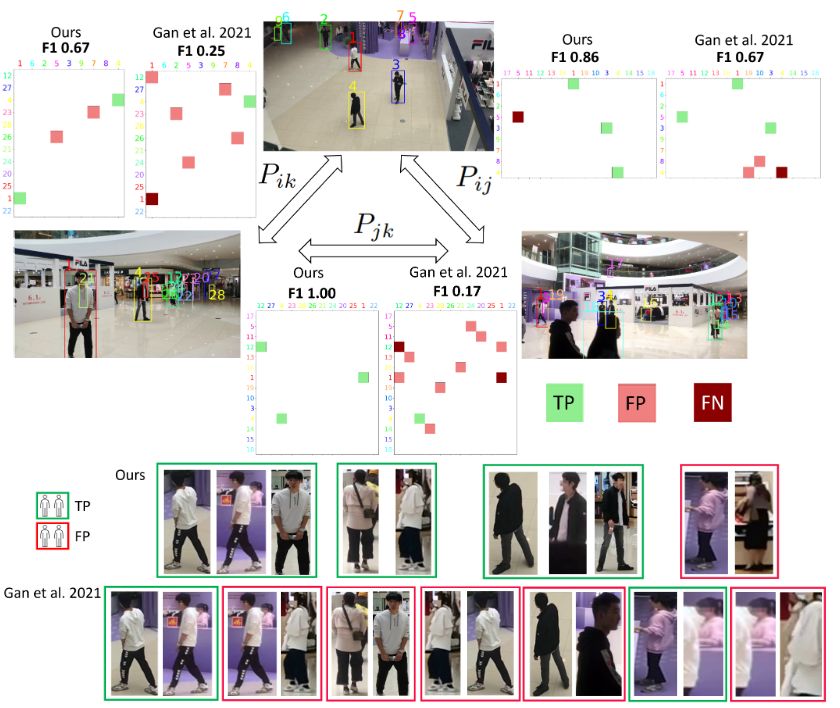
Accepted at International Conference on Computer Vision Theory and Applications (VISAPP) 2025. See publications.
-
Adaptive Prompt Tuning
The powerful CLIP model can be tuned for specialized tasks, by means of prompt tuning techniques, such as Context Optimization (CoOp) and Visual Prompt Tuning (VPT). These methods adds tokens to the prompt or model, but in a static way. We propose to dynamically refine the text prompt for the image at hand.
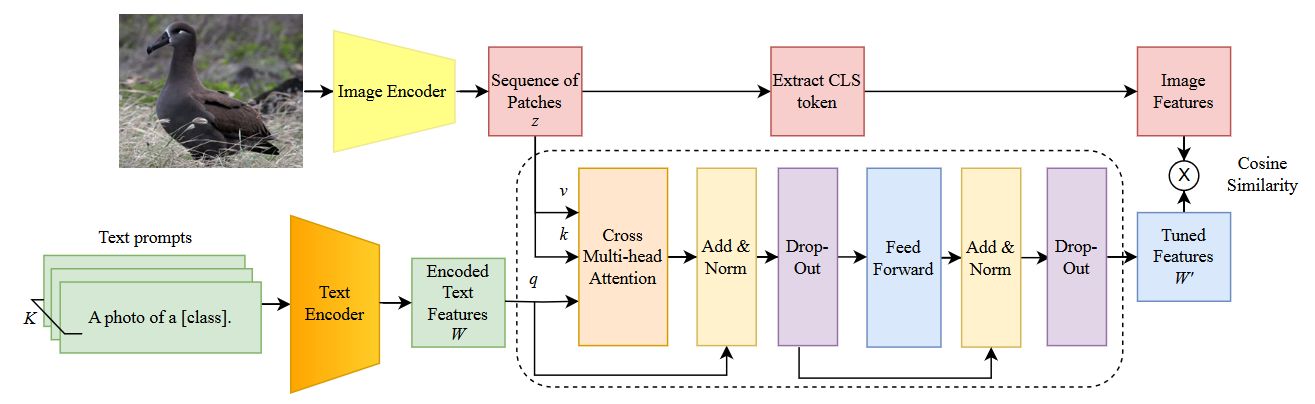
We devised a cross-attention mechanism. This enables an image-specific alignment of textual features with image patches extracted from the Vision Transformer, making the model more effective for datasets with high intra-class variance and low inter-class differences.
Accepted at International Conference on Computer Vision Theory and Applications (VISAPP) 2025. See publications.
-
FIND: Foundation Models for Industry
A new program on Foundation Models for Industry!
Great news: the research program FIND has been granted. FIND stands for Foundation for Industry: Large AI models for a resilient high-tech industry. It is about Foundation Models, i.e. modern large AI models, and how they can be applied for various use cases.

Foundation Models are booming in a wide range of disciplines, from robotics/autonomy, smart industry, chemical, to medical. We are in it for robotics/autonomy, but there are also use cases in the program from other domains that we can learn from.
The research questions are about how you can use general models for specialist tasks (deep learning), how these models can be made robust (limiting hallucinations), and signaling when they are uncertain (uncertainty estimation). Two of the PhD’ers will be co-supervised by us.
Many partners, including UvA, TU Delft, TU/e, TNO, ASML, NXP, Technolution, Canon, Kaiko, PercivAI, Signify. Proud to be building new knowledge, methods and models with this team!
-
Camouflaged Objects
We trained Grounding DINO to detect camouflaged objects, a challenging task. The image shows that the basic model cannot detect the second soldier in the first and third row. After adaptation, it can successfully find the second soldier.

-
Robot Action Planning by Active Inference
Autonomous inspection robots need to plan ahead while reasoning about several sources of uncertainty in an open world. Such inspections are performed to reduce the uncertainty about the true state of the world, for which it is important that robots manage their sensory actions so that the uncertainty in resulting observations is low.
A recent trend is the use of active inference for this type of planning problems, which is a formalism for acting and perception based on the free energy principle. The applicability of active inference is currently limited to small problems because it typically requires full policy enumeration, and it cannot directly be used to reduce state uncertainty.
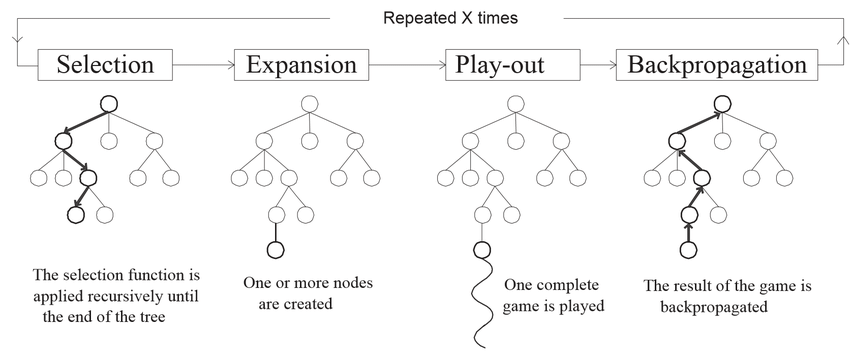
In this paper we show how active inference can be integrated in online planning algorithms for POMDPs, and we show how minimization of state uncertainty can be modeled within the active inference framework. Our planning algorithm is a tailored Monte Carlo Tree Search algorithm which uses free energy as reward signal, where we express reduction of state uncertainty in terms of free energy. In a series of experiments we show that our planning algorithm based on active inference effectively reduces state uncertainty during inspection tasks. Compared to a baseline POMDP algorithm it chooses actions that result in lower uncertainty.
-
Signals vs. Symbols at Royal Society
I was on London at the Royal Society, for a symposium and debate to go beyond the symbols vs signals dichotomy. Professors from Harvard, Stanford, Oxford, Leuven, Deepmind talked about neurosymbolic AI, continual learning, foundation models, agents, large language models, formal languages, and more.
An impressive atmosphere with statues and writings of historic scientists (e.g. Boole). Many thoughts about the future of AI: about agents having and achieving goals, using prior knowledge, reward machines, guidance through language, formal mechanisms for provability and safety guardrails.

-
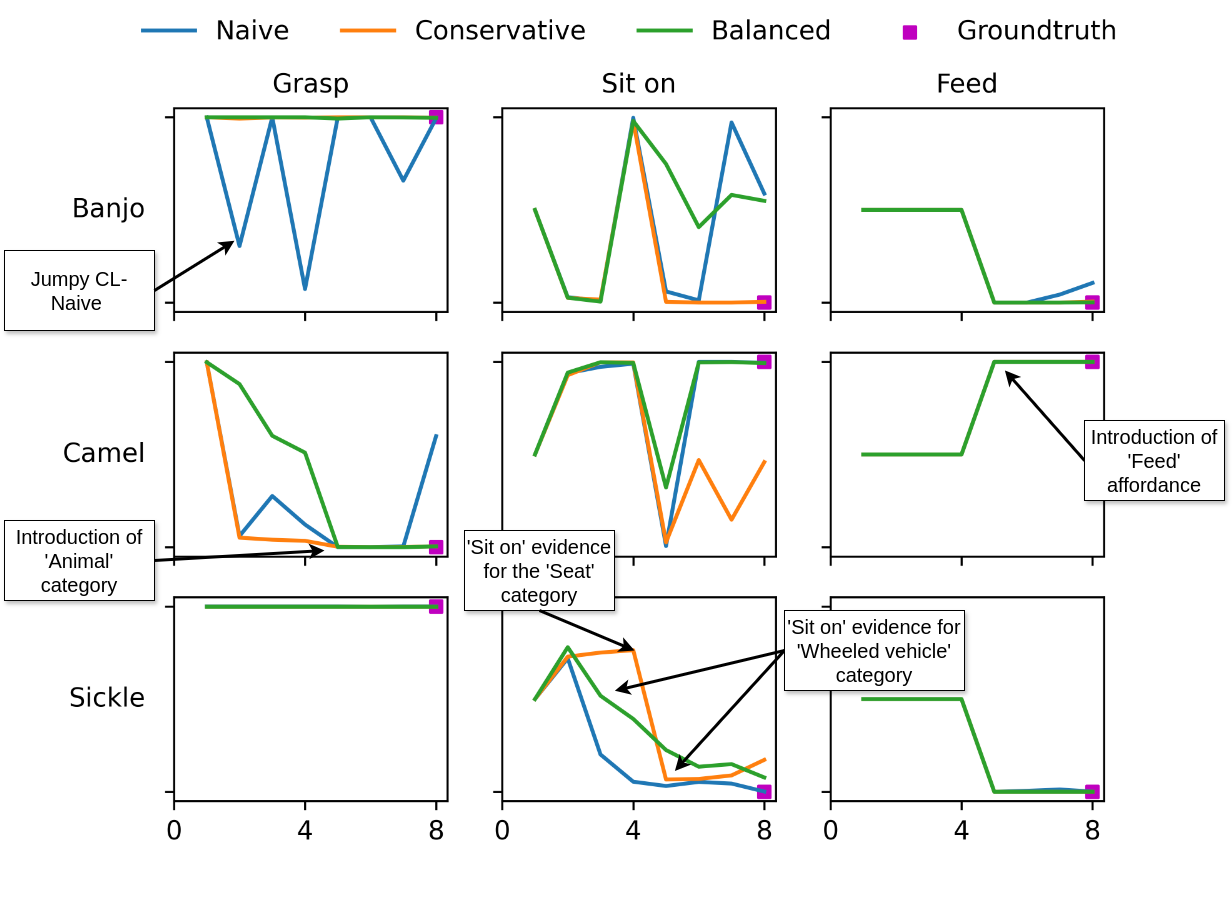
Incrementally Learning the Affordances of New Objects
A banjo can be grasped, because most musical instruments can be grasped, and it has a low weight so it can be moved and lifted. We have devised a method that can incrementally learn such affordances, also for new objects. It leverages the knowledge it has so far (e.g. most musical instruments can be grasped) and combines it with new evidence for new objects (e.g. a banjo has a low weight). The challenge: how to update knowledge & when to change beliefs.
We developed a Markov Logic Network (MLN) variant, called MLN-CLA (cumulative learning algorithm) that can do this. Some things are often true, but not always. The belief of MLN-CLA is stronger when there is more evidence towards a hypothesis. This is expressed in weights of the formulas that the MLN learns.
After having seen some objects over time, it learns the right affordances for most objects. The figure shows how this learning improves over time.
-
Better LLMs have a better understanding of the Visual World
Ever wondered if better LLMs actually have a better understanding of the visual world? As it turns out, they do! We find: an LLM’s lingual performance correlates with zero-shot performance in a CLIP-like case when using that LLM to encode the text.
To test this rigorously, we build the Visual Text Representation benchmark (ViTerB) in which a frozen vision and frozen text encoder are trained CLIP-like manner with controlled paired data - s.t. we measure the true generalisation that comes from language understanding.
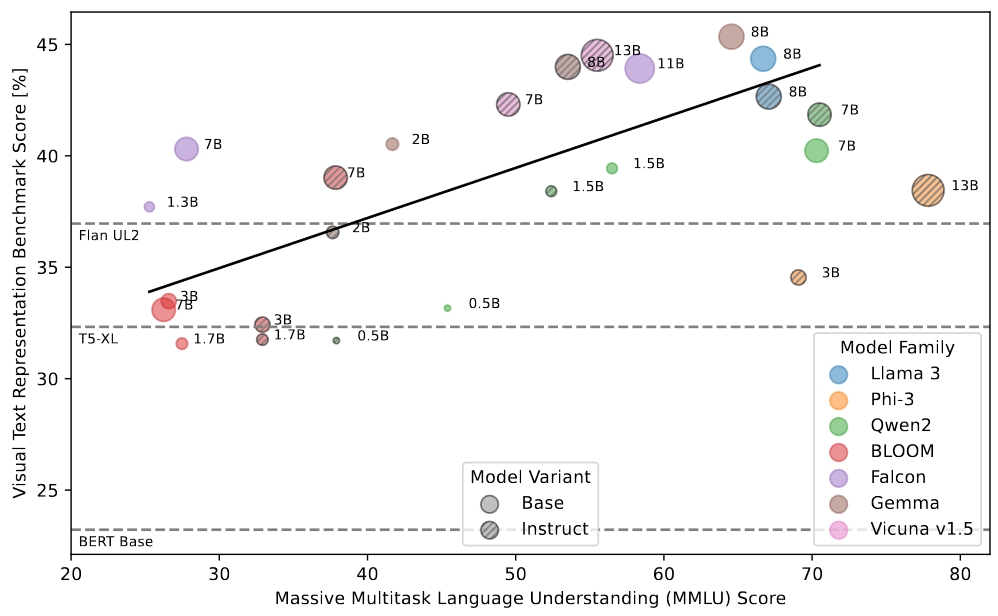
Surprisingly, we find that decoder-only LLMs actually give great representations! Better than T5, UL2 etc. So we make a new method that freezes not only vision encoder (e.g. LiT) but also uses frozen LLM decoders, we call it ShareLock.

We also train our method on CC3M and CC12M. Because of the frozen and precomputed features, training is done in 2h (and even precomputing only takes ~8h) on a single A100 GPU. Performance is also very good!

-
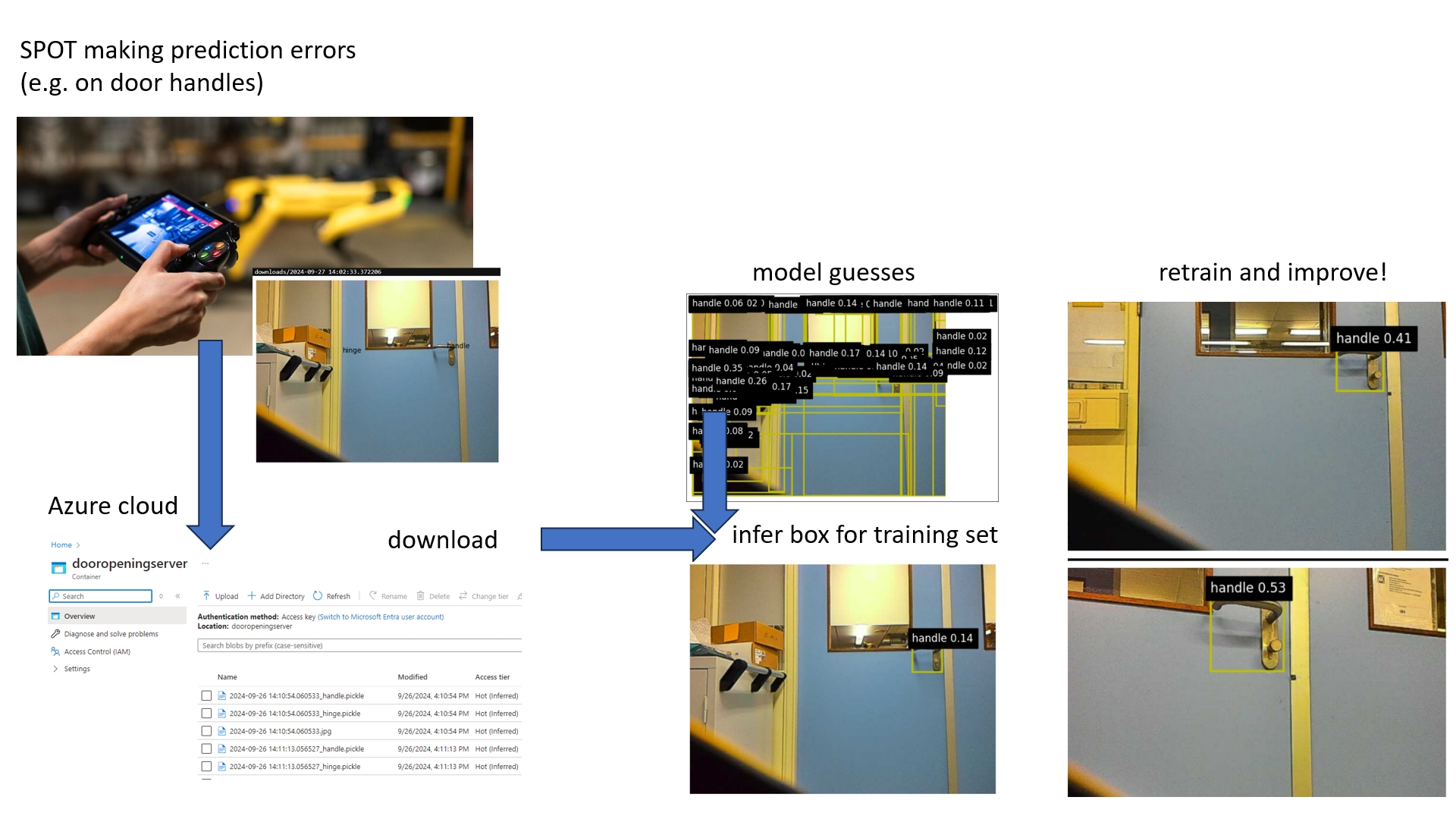
Robot Learns on the Job
Robots in the open world will encounter new situations, which may lead to lower performance. For instance, it may not recognize the desired object, such as a different type of door handle. We devised a framework in which the robot can learn on the job.
The user is the robot operator, he/she can indicate the object by clicking on it. With the current model, we do a best-effort in estimating the box for that location. This box is used for retraining the model. Of course, we do not want to forget the previous objects. To that end, we modified Grounding DINO’s tokenizer, to only update the relevant tokens, from our ICPR 2024 paper. We applied this on SPOT, where the model can now successfully learn new objects.
-
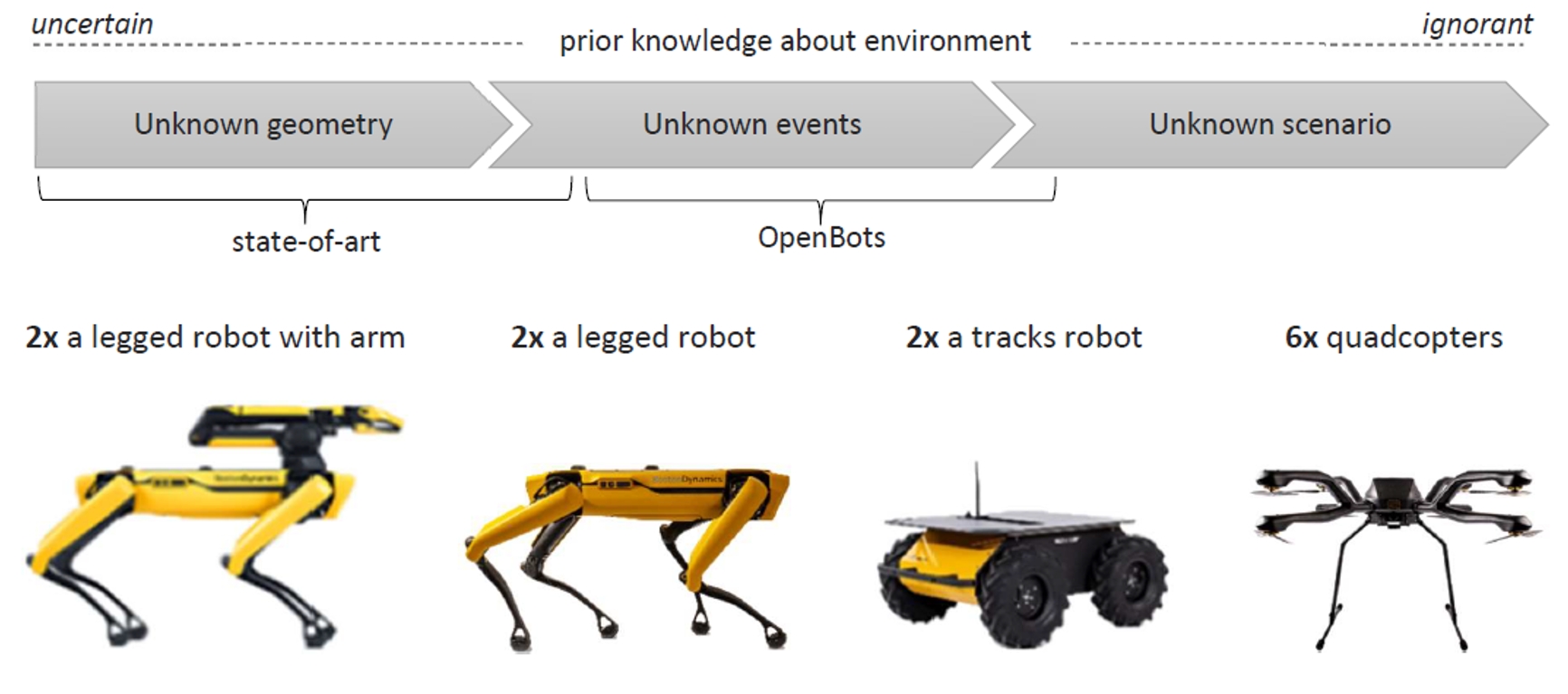
OpenBots kicked off
OpenBots: Open world autonomy of robots by common sense AI.
Advanced robots are remarkable successful in conducting a specific task, yet only when operating in static and predictable environments. Unfortunately, the operability of existing robotics stalls catastrophically when significant or unpredictable events occur, as it breaks their closed world assumption. We propose the OpenBots project to turn robots from automated systems operating in a closed-world into autonomous systems that operate in the real, open world. We will do so by injecting common sense principles into the perception and planning processes of robots to extend their artificial intelligence abilities, so that robots may solve newly encountered situations autonomously.
A collaboration with University of Amsterdam, TU Delft, Royal Marechaussee and TNO.
Today was the kickoff,

Sponsored by NWO Open Technology Programme, Royal Marechaussee and TNO. Press release. News item.
-
Guiding Segment-Anything Model (SAM)
Localizing object parts precisely is essential for tasks such as object recognition and robotic manipulation. Recent part segmentation methods require extensive training data and labor-intensive annotations. Segment-Anything Model (SAM) has demonstrated good performance on a wide range of segmentation problems, but it requires (manual) positional prompts to guide it where to segment. Furthermore, since it has been trained on full objects instead of object parts, it is prone to over-segmentation of parts.
To address this, we propose a novel approach that guides SAM towards the relevant object parts. Our method learns positional prompts from coarse patch annotations that are easier and cheaper to acquire. We train classifiers on image patches to identify part classes and aggregate patches into regions of interest (ROIs) with positional prompts. SAM is conditioned on these ROIs and prompts.
We call our method ‘Guided SAM’. It enhances efficiency and reduces manual effort, allowing effective part segmentation with minimal labeled data. It improves the average IoU on state of the art models from 0.37 to 0.49, while requiring five times less annotations.

Part of the FaRADAI project. Accepted at International Conference on Pattern Recognition, 2024.
-
Learning Objects without Forgetting
Our method recognizes and locates new objects, without forgetting the known objects. The latter in particular is a disadvantageous problem in practical applications: you want the model to really learn, and not just remember the most recently learned things and forget the rest.
We have improved a Vision-Language Model (VLM) by making the ‘register’ of known objects (LLM tokens) expandable. On top of that, we ensure that the objects differ from each other as much as possible, with some mathematical tricks.
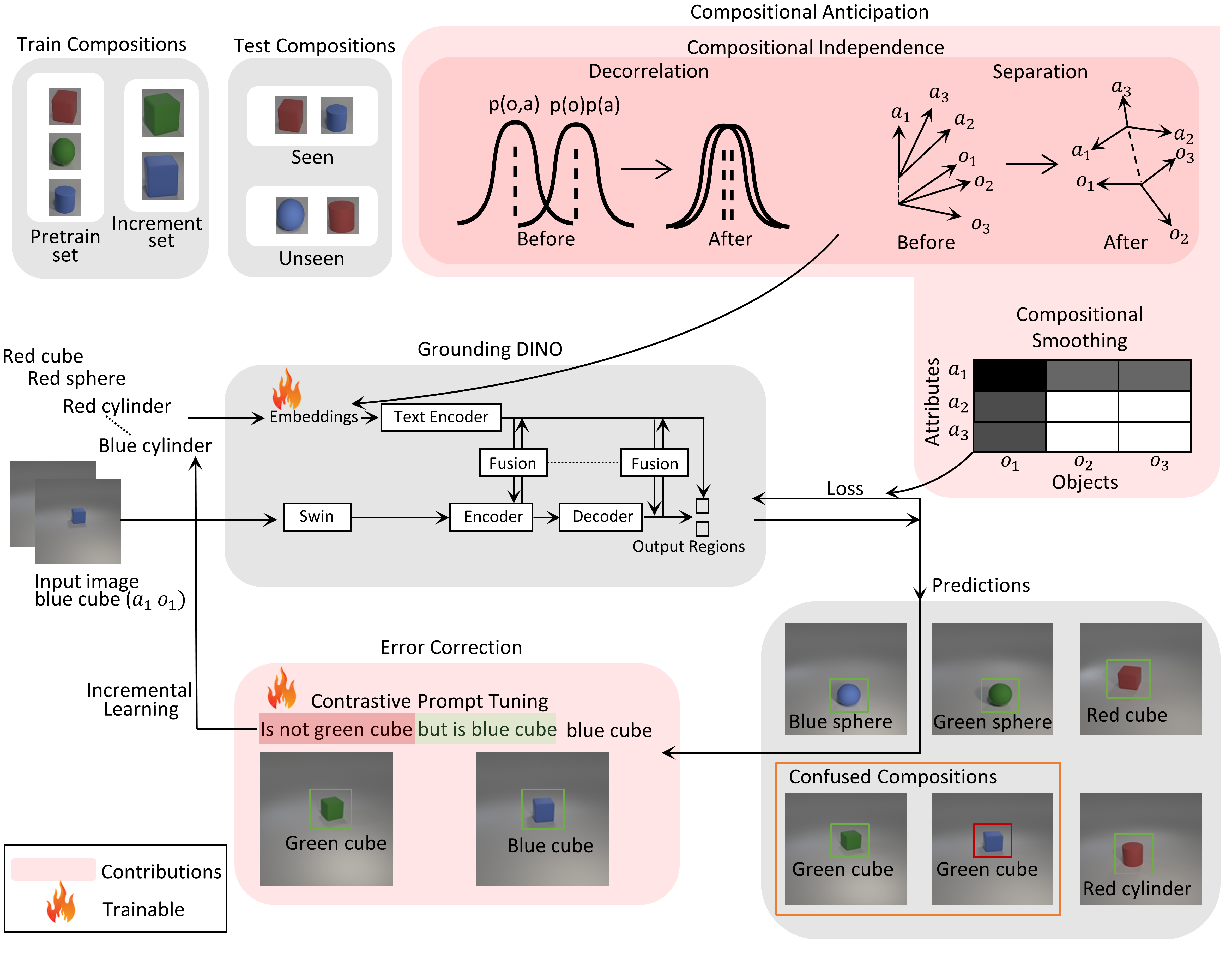
Part of the FaRADAI project. Accepted at International Conference on Pattern Recognition, 2024.
-
Scaling 3D Reasoning
Large multimodal models (LMMs) are useful for many robotics capabilities, including spatial reasoning and semantic scene understanding. However, they do not scale well to large environments.
We decompose the environment into smaller rooms. Each room is a node in a graph. Scalability is achieved by expanding the graph to new rooms iteratively.
Connected rooms are representated by relations in the graph. Various routes become apparent in this way.
Given the objects found in the rooms, the robot can reason about the safest route.
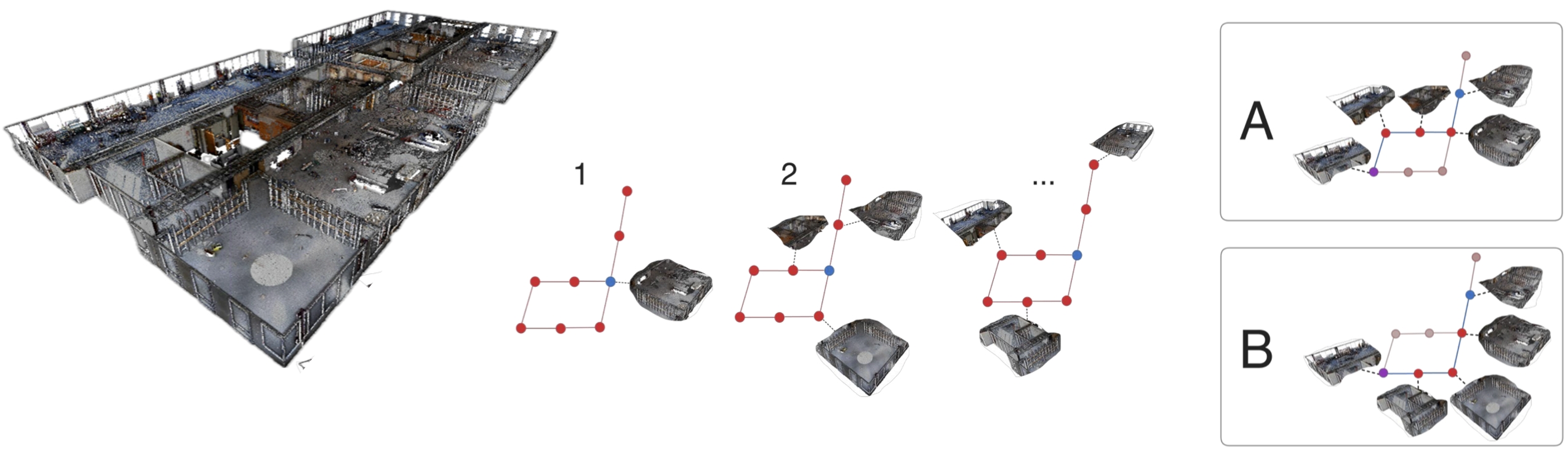
Accepted at the Robotics: Science and Systems, Semantics for Robotics, 2024.
-
Probabilistic Logical Programming
Understanding situations and scenes, often requires relational reasoning. For instance, a situation is dangerous because the cyclist is getting very close to the car.
Relational reasoning can be done by inductive logic programming (ILP). A problem is that many ILP methods are incapable of dealing with perceptual flaws and probabilities, while many real-world observations are inherently uncertain.
We propose Propper, which extends ILP with a neurosymbolic inference, to deal with perceptual uncertainty and errors. We introduce a continuous criterion for hypothesis selection and a relaxation of the hypothesis constrainer.
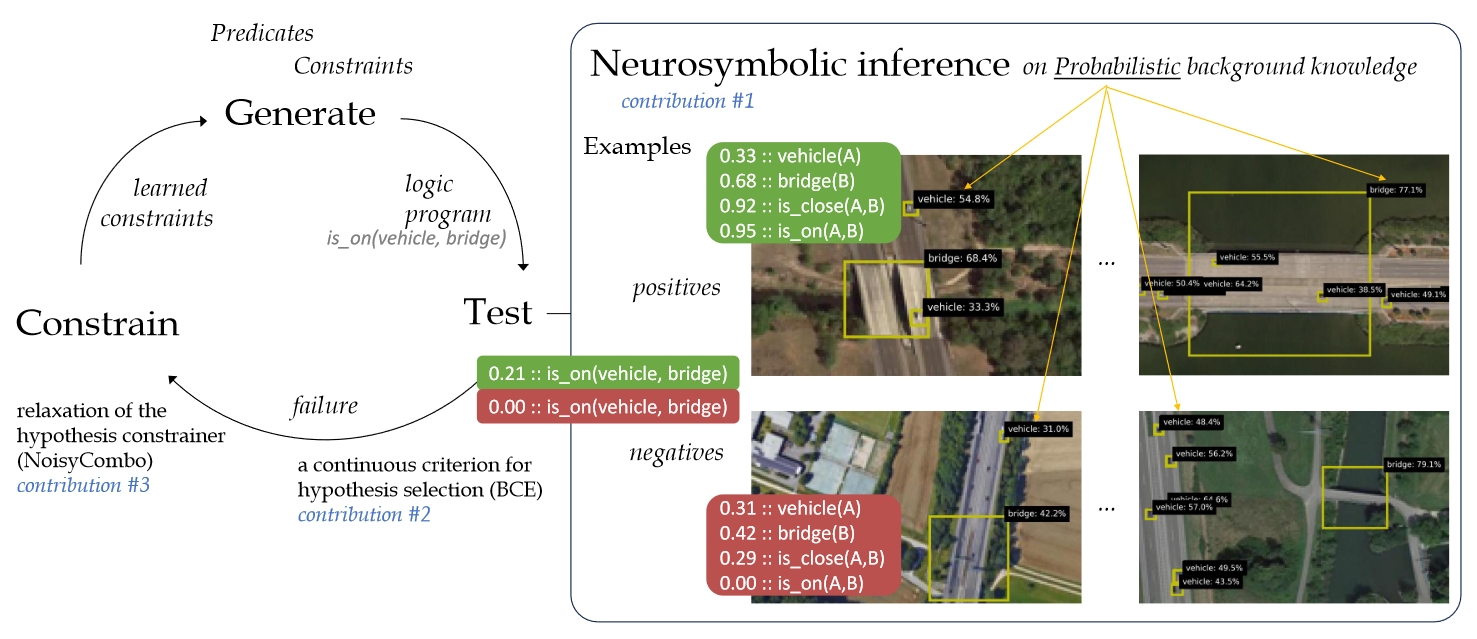
For relational patterns in noisy images, Propper can learn effective logical programs from as few as 8 examples. It outperforms binary ILP and statistical models such as a Graph Neural Network.
Accepted at the International Conference on Logic Programming, 2024.
-
Reasoning about Affordances
If your robot needs to stand on an object to look on the other side, the object should be strong enough to hold the robot.
The SOTA methods do not take the physicality of the robot into account when selecting actions. We propose a dialogue that is able to reason about physicality and suitable objects for achieving the goal.
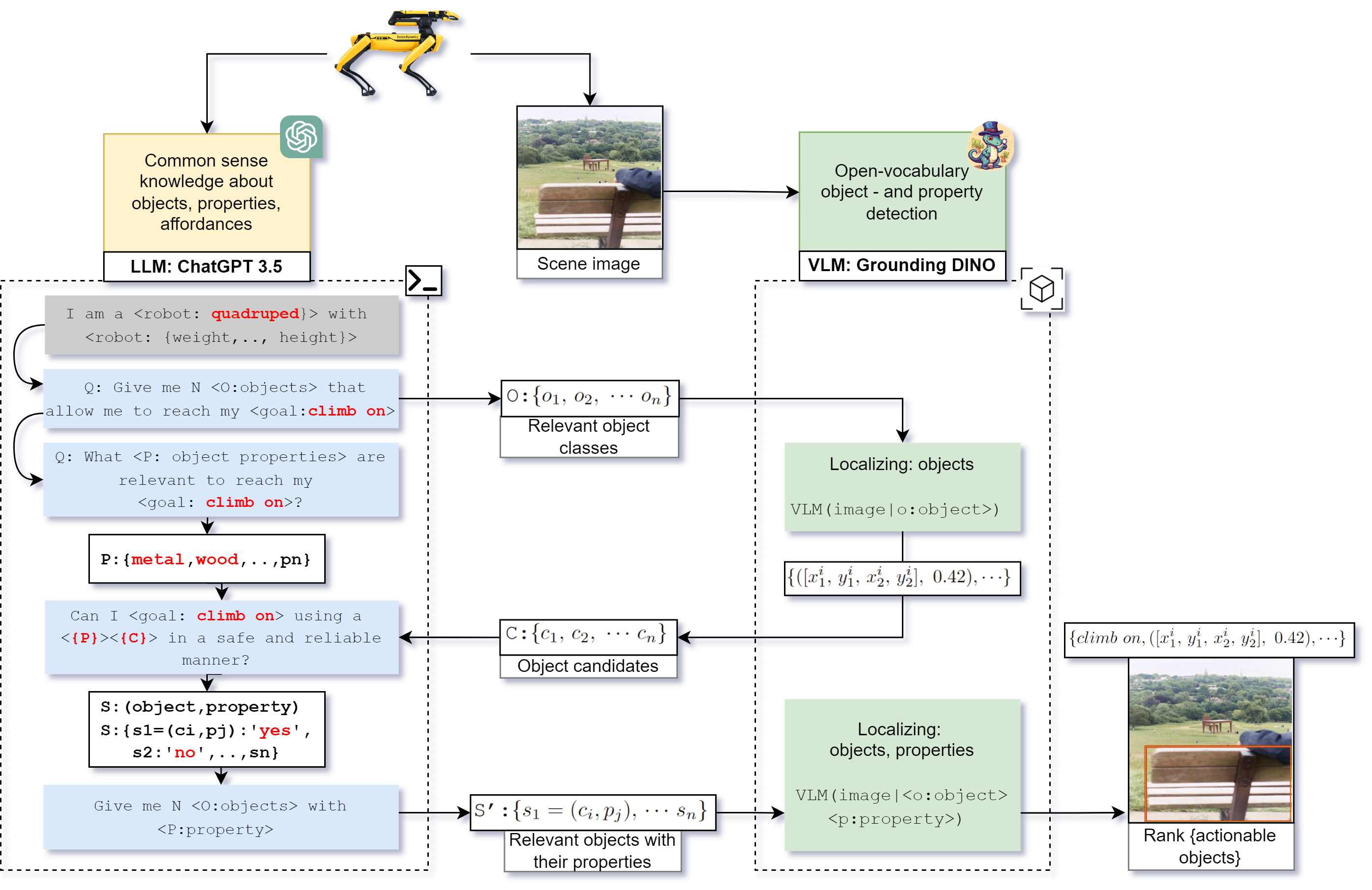
A large language model (LLM) is connected with a language-vision model (VLM). The LLM harnesses knowledge about the physical world, whereas the VLM is able to recognize objects.
We extended the VLM with a notion of physical properties of the objects. For instance, a box of carton is not strong enough, but a wooden box would be suitable.

Accepted at RSS 2024, Semantic Reasoning and Goal Understanding in Robotics.
-
Uncertainty Quantification for Robotic Navigation
For navigation of robots, image segmentation is an important component to determining a terrain’s traversability. For safe and efficient navigation, it is key to assess the uncertainty of the predicted segments. Current uncertainty estimation methods are limited to a specific choice of model architecture, are costly in terms of training time, require large memory for inference (ensembles), or involve complex model architectures (energy-based, hyperbolic, masking).
We propose a simple, light-weight module that can be connected to any pretrained image segmentation model, regardless of its architecture, with marginal additional computation cost because it reuses the model’s backbone (depicted below).

Our module is based on maximum separation of the segmentation classes by respective prototype vectors. This optimizes the probability that out-of-distribution segments are projected in between the prototype vectors. The uncertainty value in the classification label is obtained from the distance to the nearest prototype. We demonstrate the effectiveness of our module for terrain segmentation and anomaly detection.
Our paper was accepted at ICRA 2024 Off-road Autonomy workshop.
-
Efficient Correction of Vision-Language Models
For robotics, vision-language models (VLMs) are the go-to, because they have zero-shot capabilities. They can look for new objects based on textual prompts, which often works surprisingly good. But, not always…
We investigated whether a VLM, GLIP, can be used to find doors and their openers. It can do a pretty good job, but it’s far from perfect (see the second image below).

So, we let the robot do its best, to find as most as it can. Next, we involve the user to correct the wrong predictions. Finally, the model is retrained with the corrections (see the third image above). With a spatial reasoner - openers are close to the door - the predictions can be improved further (fourth image).
This is a very effective strategy. The user only needs to label a few instances, i.e. the mistakes. This is very efficient.
The paper was accepted at International Conference on Pattern Recognition and Artificial Intelligence (ICPRAI).
-
Affordance Perception
Mobile robot platforms will increasingly be tasked with activities that involve grasping and manipulating objects in open world environments. Affordance understanding provides a robot with means to realise its goals and execute its tasks, e.g. to achieve autonomous navigation in unknown buildings where it has to find doors and ways to open these. In order to get actionable suggestions, robots need to be able to distinguish subtle differences between objects, as they may result in different action sequences: doorknobs require grasp and twist, while handlebars require grasp and push.
We improve affordance perception for a robot in an open-world setting. Our contribution is threefold: (1) We provide an affordance representation with precise, actionable affordances; (2) We connect this knowledge base to a foundational vision-language models (VLM) and prompt the VLM for a wider variety of new and unseen objects; (3) We apply a human-in-the-loop for corrections on the output of the VLM.
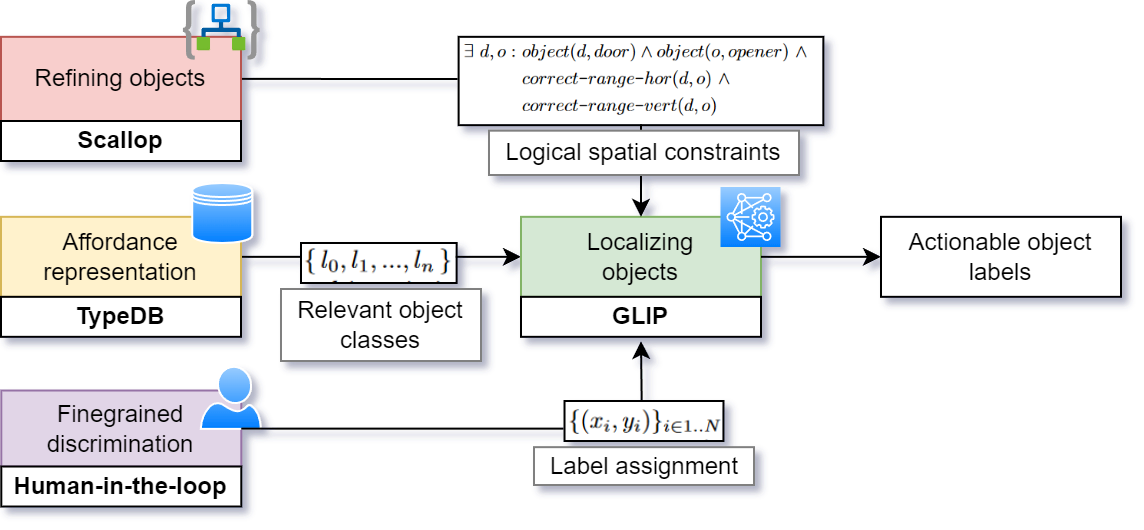
The mix of affordance representation, image detection and a human-in-the-loop is effective for a robot to search for objects to achieve its goals. We have demonstrated this in a scenario of finding various doors and the many different ways to open them.
The paper was accepted at International Conference on Pattern Recognition and Artificial Intelligence (ICPRAI).
-
Inductive Logic Programming
We are working on a new area that we find fascinating: Inductive Logic Programming (ILP). ILP is helpful to find logical patterns, e.g. in your object detections. We argue that it enables Understanding, as it outputs programs about relations between objects, in terms of first-order logic.
We have some interesting findings: ILP can find complex patterns better than statistical models, even the advanced ones such as a Graph Neural Network. Moreover, it’s explainable!
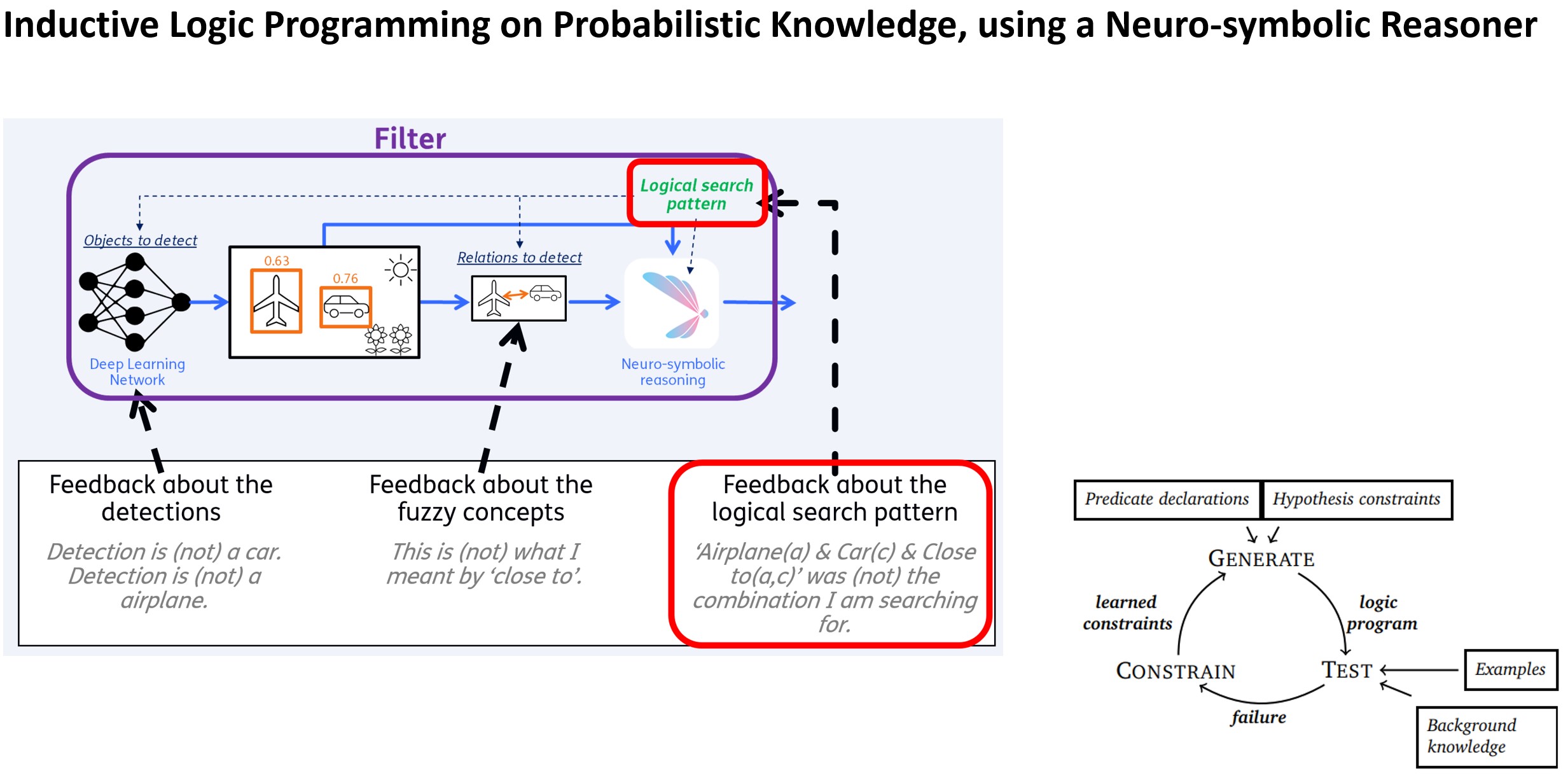
Can you find the pattern in the images below? ILP can!

-
Presenting zero- and few-shot learning at VISAPP, Rome
Presenting our work on zero- and few-shot learning at the VISAPP conference in Rome.
We synthesize visual classifiers via semantic knowledge about the classes. These synthesized classifiers can classify novel, unseen classes due to semantic transfer. The classifiers are ordinary classifiers that can be optimized further with a few training labels once they become available.

A good crowd with an interesting discussion afterwards. Happy to receiving positive feedback and many good questions.
-
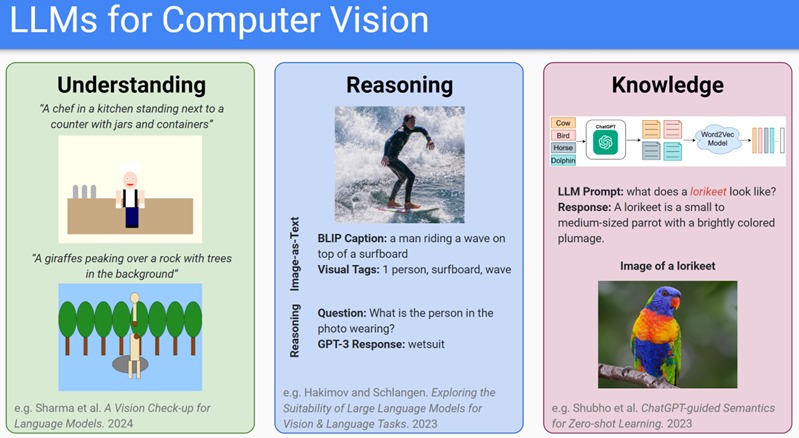
LLMs for Computer Vision
Many types of knowledge can be extracted from Large Language Models (LLMs), but do they also know about the visual world around us? Yes, they do! LLMs can tell us about visual properties of animals, for instance. Even fine-grained properties such as specific patterns and colors.
We exploited this and trained a model for animal classification without human labeling of these properties. We just took the LLMs answers as groundtruth, instead of human annotation.
Interestingly, it works just as well as human annotations.The research is done by Jona, our student, who is also going on an ELLIS exchange with the University of Copenhagen with the renowned professor Serge Belongie.
-
Our team at NeurIPS 2023
With two nice papers, my team was present at NeurIPS 2023. Great to see so many interesting topics and people!

-
Creating and Updating Classifiers from Prior Knowledge
Paper accepted at International Conference on Computer Vision Theory and Applications (VISAPP).
It’s about visual recognition of new classes from earlier ones, by a mapping derived from attributes or a Large Language Model (LLM). For instance, the new bird (left) is recognized by mixing the properties of known birds (right). Such knowledge is available from LLMs, in a way that is almost as good as expert knowledge (312 manual attributes).
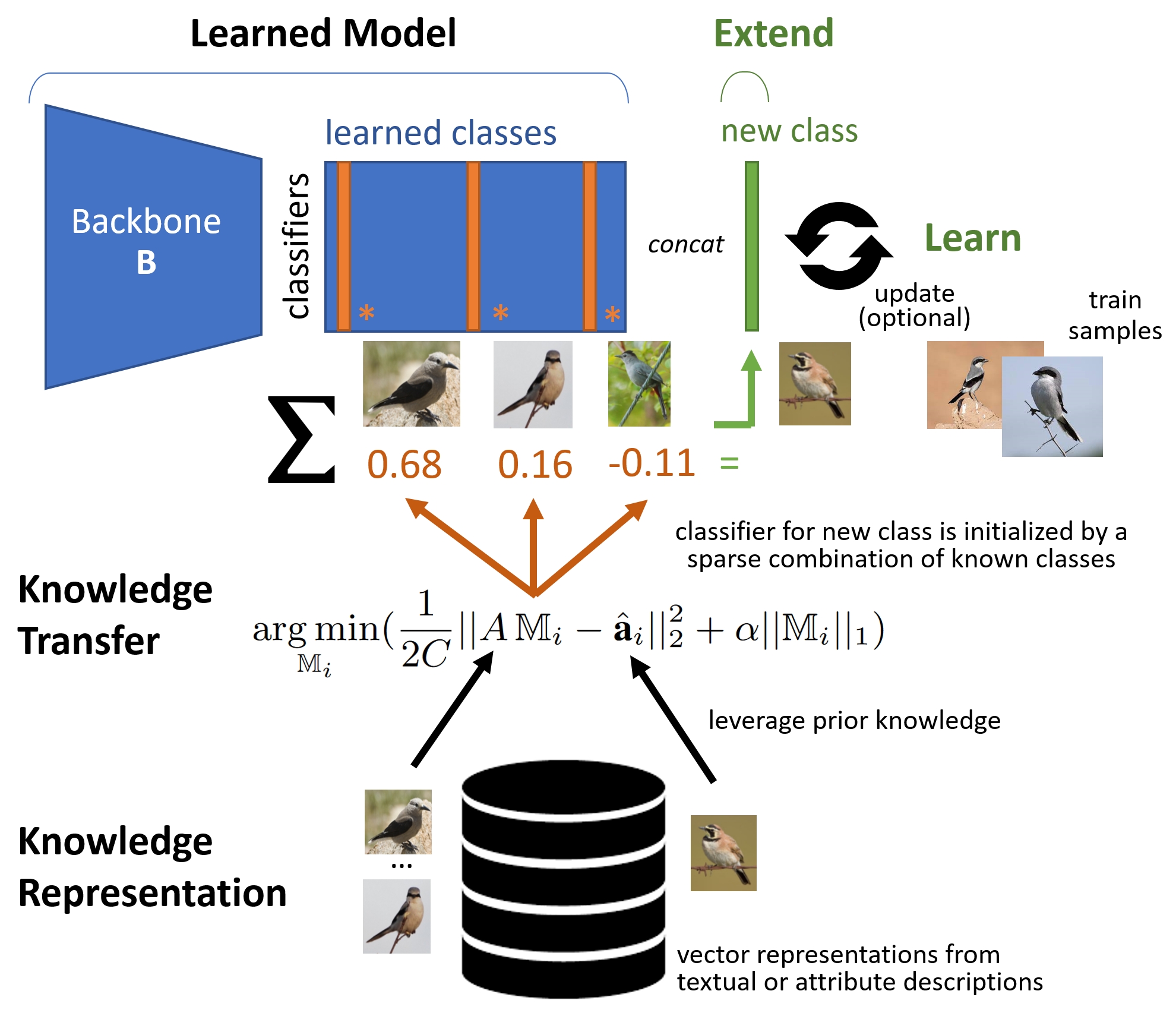
The reviewers were very positive: highest scores for relevance, second largest scores for overall, resulting in an Oral presentation of 25 minutes in Rome, February 2024. Joint work with Klamer Schutte, Maarten Kruithof, Wyke Pereboom-Huizinga, Frank Ruis and Hugo Kuijf. See Publications for more information.
-
Efficient Transfer for Objects using Diffusion
Our paper was accepted at the NeurIPS workshop on Diffusion Models! It’s about efficient domain transfer, using semi-supervised learning. A model was trained on frontal images from MS-COCO, but we want to apply it to drone images that look very different. The objects are much smaller and the viewpoint is very different.
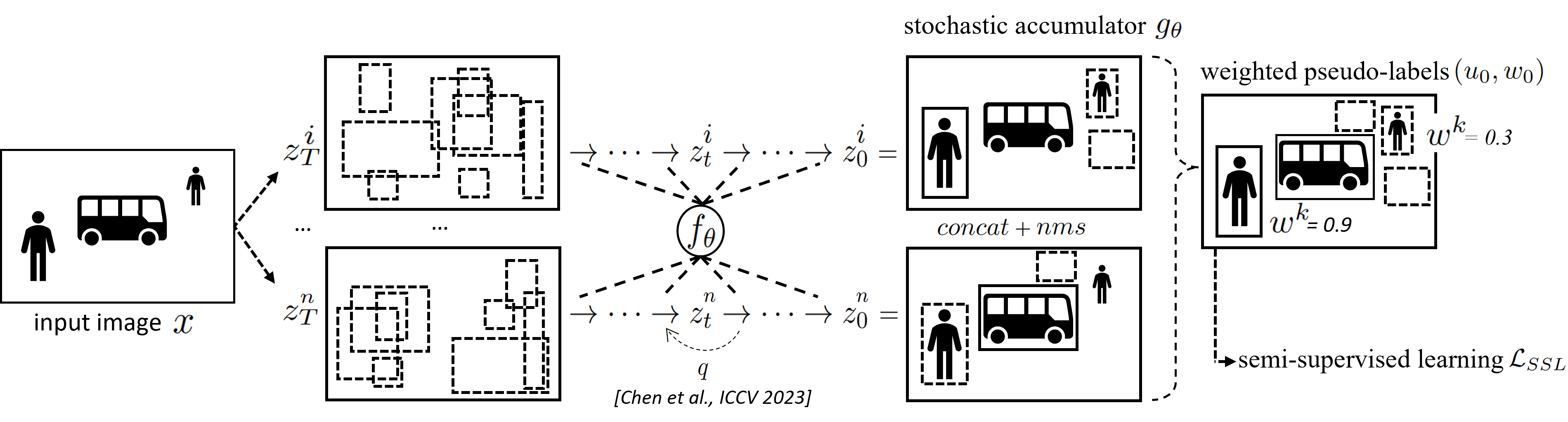
First, we improve the recall of the method, by accumulating detections. Next, we use the improved detections as pseudo-labels for the unlabeled images, combined with 10 labeled images, in a semi-supervised setup.
The performance can be improved, as shown below, from left (original model), middle (improved recall) to right (semi-supervised learning).

See Publications for more information.
-
IEEE Robotic Computing
Our paper was accepted at IEEE Robotic Computing! It’s about learning a robotic agent to pay less attention to accidental appearances in the environment, such as the wall colors.
Current methods get trapped, because they learn to search for the sofa nearby white wall colors. Usually living rooms have white-colored walls. We have funny videos of such traps, when the wall color is different than during training (see Videos for a demo).
Our method applies an augmentation in language space, saying that a wall color can also be red or blue etc. We add such augmentation vectors to the visual feature vector before it goes into the agent’s model, such that it needs to generalize for such changes.
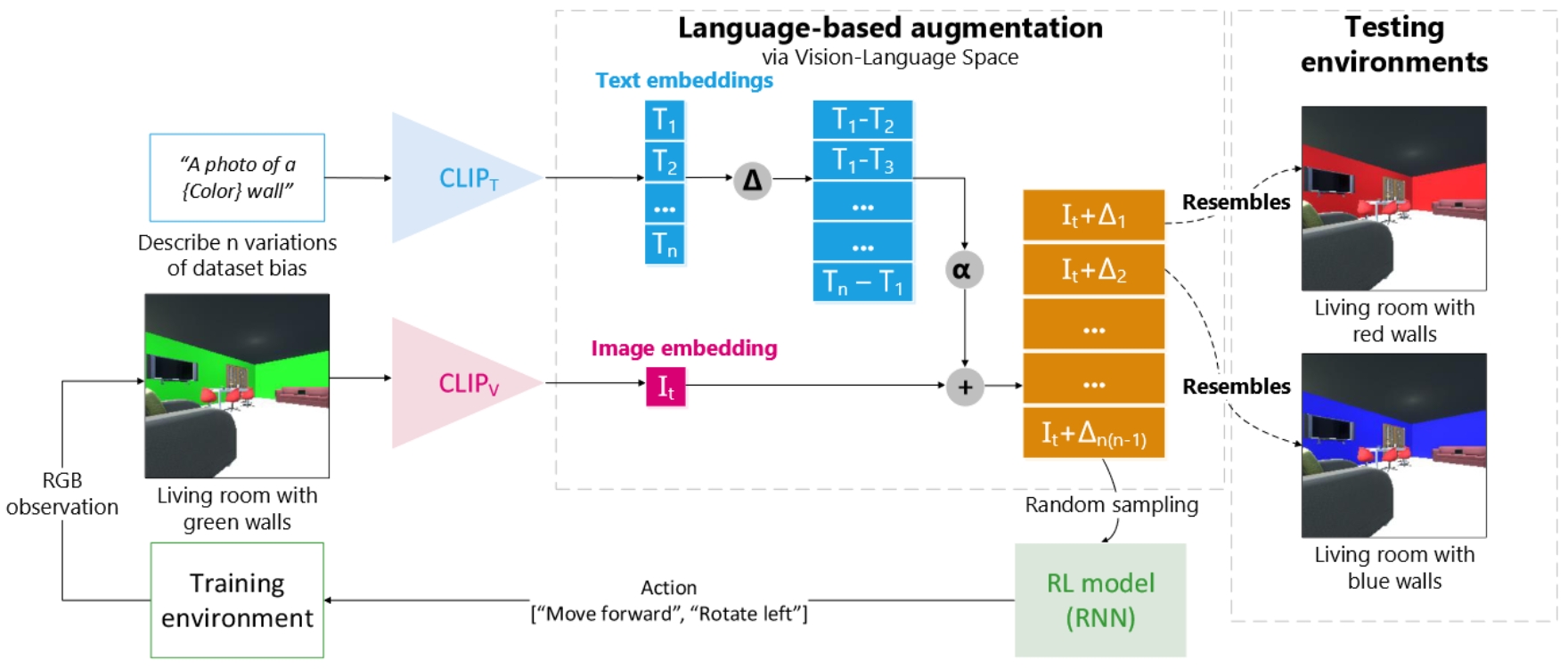
The reviewers were very positive about this idea and its impact. See Publications for more information, demo and code.
-
Label Selection and Pseudo-Labels
We presented our work on efficient transfer learning at IEEE ICIP 2023, Kuala Lumpur. Our method selects representative and diverse labels, and generates pseudo-labels that prove to be helpful for efficient learning in new domains.

Sponsored by DARPA.
-
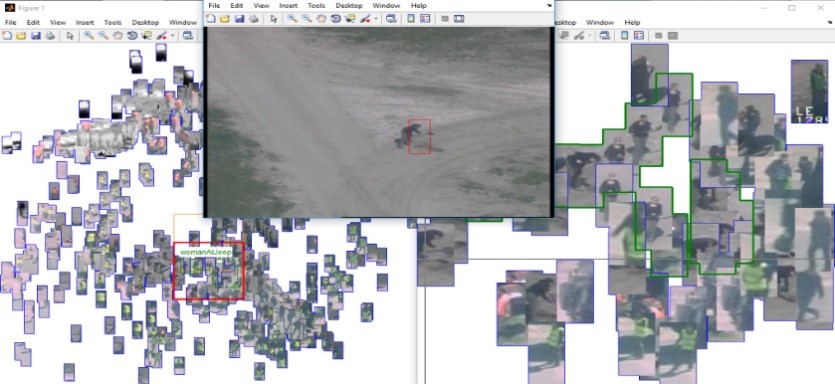
How to Open the Door?
It seems like a simple question: how to open the door? But for a robot such as SPOT, this is not easy. Doors can be opened by various openers, from handles to knobs and push bars. It matters a lot for the robot, because it needs to perform a different action for each opener - i.e. how to grasp and move it.

With a language-vision model, we were able to detect the various openers. But it was not able to distinguish between them, because language is not precise enough.
With a clustering technique, we were quickly able to make the distinction. In the image, you can see that the different door openers are clustered together. The different clusters are indicated by their center, which is most representative. This is visualized by the images with the box around them.
-
Diffusing More Objects
Diffusion models are a popular family of neural networks for generative AI. They can generate new samples such as images. Recently, researchers explore whether other types of outputs can be generated. For instance, object detections: bounding boxes with a class label and confidence score.
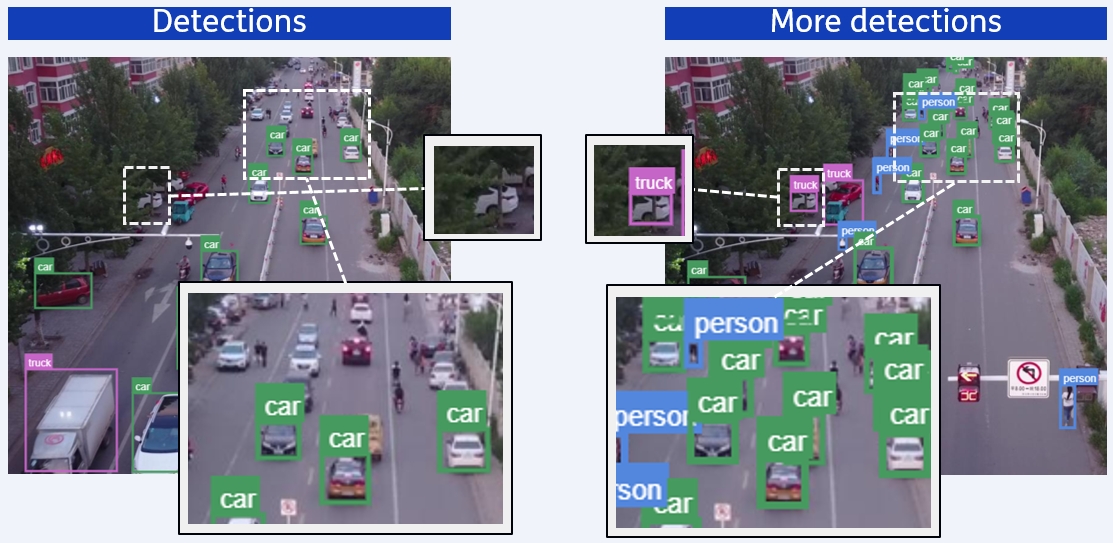
Diffusion models are stochastic by nature, because each output is a different generation. We have leveraged the stochasticity to retry the generation of object predictions for hard cases, such as small objects or low-contrast image regions. This idea works, as you can see in the image above: more objects are detected.
-
Neural Networks are Graphs
Neural networks are actually graphs, i.e. computation graphs.
At the TAG workshop at ICML, we showed that interesting properties about a neural network can be learned from the network’s weights. For instance, representing each image as a single neural network (SIREN), and then learning a label from those networks’ weights, to classify the image.
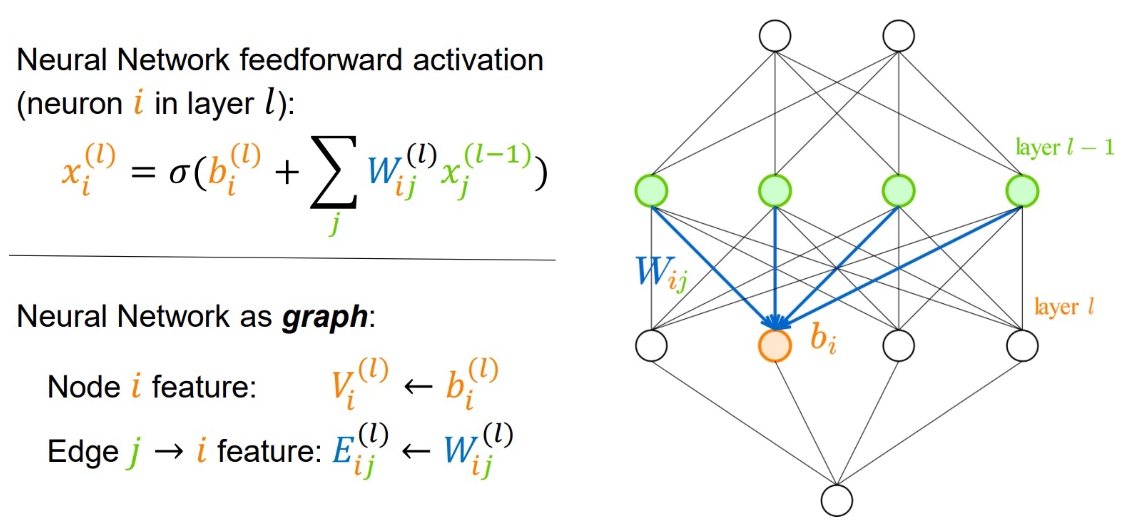
Although this is a detour, it is interesting research, because it paves the way for more advanced analyses of neural networks. For instance, recently other researchers have predicted the robustness of neural networks based on their weights.
-
Aerial Image Segmentation
Image segmentation is key to distinguish the various elements that are in a visual scene. Common models are trained on frontal views, which does not work for aerial images. To train a model for aerial images, a lot of labeled images are required, and labeling of segmentations is time-consuming.
We propose to make clusters of image segments and to label only those clusters. The clustering is based on spatial feature maps, taken from intermediate embeddings of a self-supervised model. Labeling clusters is very easy and takes almost no time.

Here you see a result of 50 such labels. Not perfect, but already useful, while only requiring a few minutes.
-
Transferring Knowledge to New Classes
Sometimes for a new class there are no training samples yet. This makes the standard supervised learning procedure impossible. To correctly classify a new class, prior knowledge about that class is required.

We leverage ChatGPT’s descriptions of classes. Via language models we reconstruct the new class via sparse linear estimation.
Very effective: on CUB with 200 bird classes, it achieves an accuracy of 62%.
It also provides a kickstart for further learning when few images of the class become available. -
ICML
David presented our paper at ICML, Hawai. The paper was about object-centric representations. The popular method Slot Attention was improved by a new way of learning good image features.

The new learning function involves optimal transport. Changing the cost between features during the learning, led to better focus on the objects. This resulted in better object discovery: segmenting new objects in visual scenes.
Good to see that many people were interested!
-
OpenBots
Project granted with University of Amsterdam (prof. Cees Snoek), TU Delft (prof. Robert Babuska and Joris Sijs), Marechaussee (Linda Terlouw, Bas van Hulst, Anne Steenbergen) and TNO (Judith Dijk and me)! Five PhD researchers will work on robots in an open world, by perception and planning using common sense knowledge.
Getting advanced robots to perform specific tasks successfully using artificial intelligence, including those in unpredictable environments and new situations.
Funded by NWO Open Technology Program, Marechaussee and TNO. Press release.
-
Neuro-Symbolic Programming
How to find door handles inside a house, while many other things in the house look like handles? Not straightforward! Especially if your model is uncertain about its predictions about doors and handles.
Neuro-symbolic programming to the rescue. It can leverage expert knowledge on top of deep learning models. It enables probablistic reasoning, taking into account uncertainties. You have to define the situation of interest by first-order logic. This is nice because it is symbolic. The good part is that you don’t have to keep track of all hypotheses and variables yourself, the program will do this for you. As inputs it takes all of the predictions, even the ones with low confidence. The program will do the sense-making for you.

You do not even need to train the underlying deep learning model(s), because you can use vision-language models in a zero-shot manner. That is, the neuro-symbolic program is agnostic about where the input predictions come from. Therefore I also see a strong potential when there are different models that need to be interpreted. These models can even come from different data modalities or platforms.
The illustration shows various examples from finding two abandoned helicopters in satellite images and helping SPOT to find the handle that opens the door.
Such a neuro-symbolic program can also be improved after user feedback. This optimization can be done with as few as 7 feedbacks only about yes/not interesting. Gaussian Process optimization is effective to boost the program’s performance.
-
Improved Localization of Objects in Context
Our paper got accepted by ICRA’s Pretraining for Robotics!
We recognize affordances in images. With this, a robot (e.g. SPOT) can find objects in images, that have a particular use for achieving its goal. For instance, opening a door by manipulating the handle.
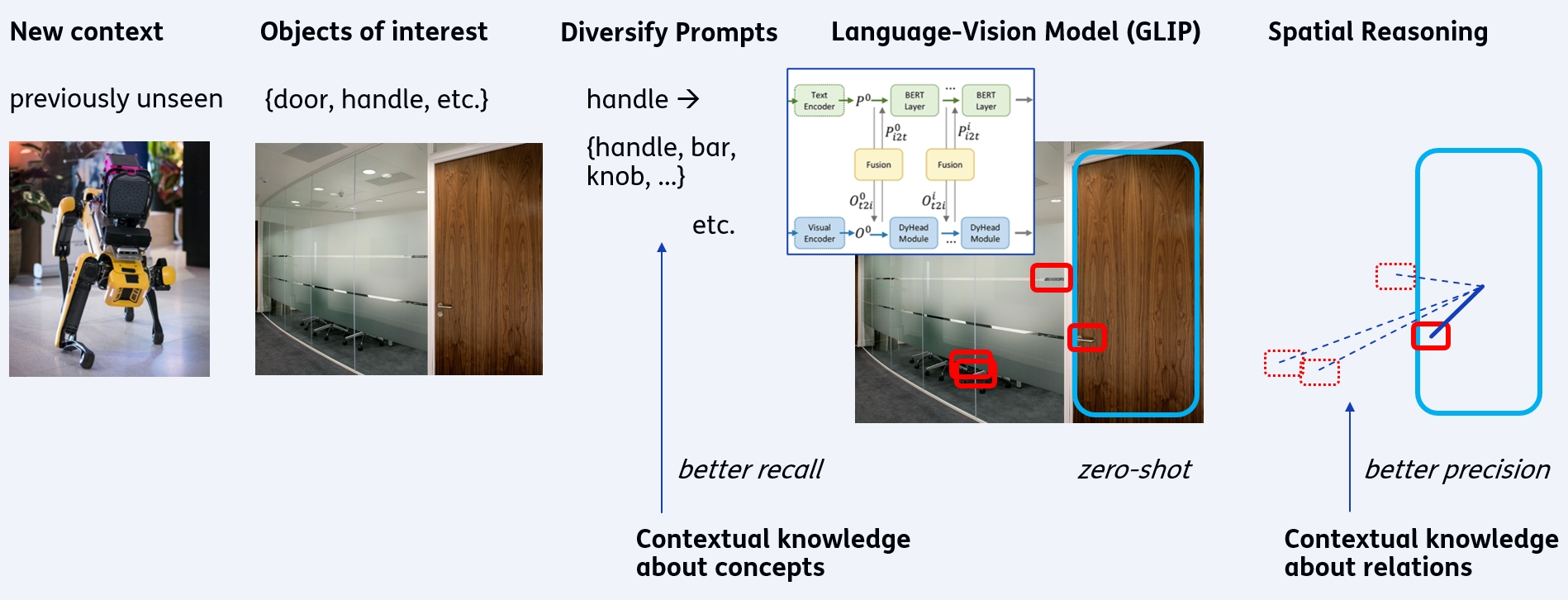
Our method finds such objects better, by leveraging prior knowledge. We improve GLIP, which is a language-vision model to find objects in images. We improve its inputs, by diversifying the textual prompts (a door can also be opened by a push bar instead of a handle). We also improve its outputs, by verification of the found objects, by checking their context (a handle should be close to the door).

A valuable asset for for robots searching for various objects without pretraining!
Paper at ICRA 2023 (see Publications). Funded by TNO Appl.AI program, SNOW project.
-
Slot Attention with Tiebreaking
Slot attention is a powerful method for object-centric modeling in images and videos. But it is limited in separating similar objects. We extend it with an attention module based on optimal transport, to improve such tie-breaking.
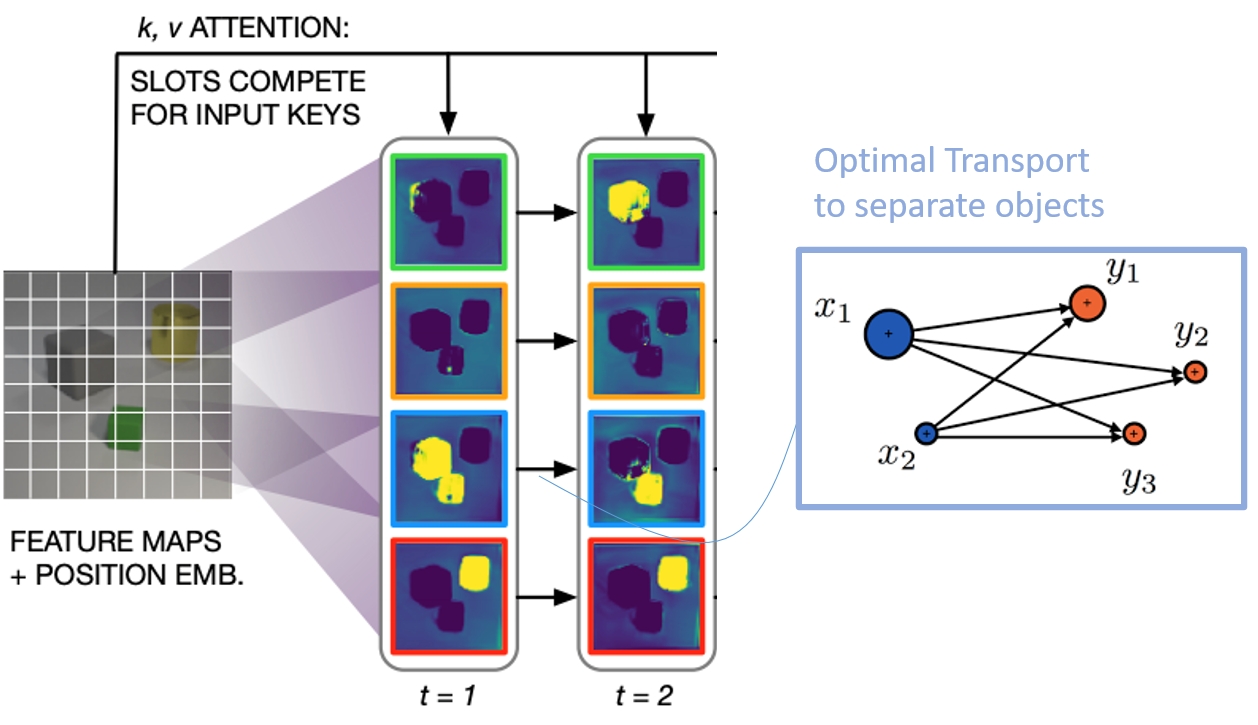
In the illustration below, you can see the original (left) and ours (right) for two input images (rows) which is split into slots. The slots should describe the objects. For the original, the objects break into parts. Our variant keeps objects together.

We propose MESH (Minimize Entropy of Sinkhorn): a cross-attention module that combines the tiebreaking properties of unregularized optimal transport with the speed of regularized optimal transport. We evaluate slot attention using MESH on multiple object-centric learning benchmarks and find significant improvements over slot attention in every setting.
Paper at ICML 2023 (see Publications). Funded by NWO Efficient Deep Learning and TNO Appl.AI’s Scientific Exploration.
-
Diffusion Models without Labels
Generative AI requires labeled data to obtain stellar results. Check our CVPR2023 paper by Vincent Tao Hu and David Zhang. We instead exploit the flexibility of self-supervision signals for diffusion models without labels. With Cees Snoek and Yuki Asano, University of Amsterdam.
Funded by NWO Efficient Deep Learning and TNO Appl.AI’s Scientific Exploration.
-
Understanding Situations by Spatial Relations
Spatial configurations of multiple objects in images can tell us something about what is going on. Here you see the result of searching for two aligned helicopters without any other objects nearby.

Another example is a helicopter on a ship.

The results are obtained by probabilistic spatial reasoning. We used Scallop for this purpose, a neuro-symbolic programming framework (NeurIPS 2021). The program consists of multiple relations such as: on(a, b), nearby(a, b), facing(a, b), next-to(a, b), classname(a), etc.
-
Self-Guided Diffusion Models @ CVPR 2023
There is a revolution going on in the field of image generation by a new type of models called diffusion models. Examples are Dall-E and StableDiffusion. It was shown that generated images get better when guiding the diffusion model, e.g., with a textual description or semantic token from another classifier. We were curious whether we can guide them also with a self-supervised learning signal, which is beneficial because it requires no annotation effort for training of the model.
We use self-learned bounding boxes from another method (LOST, BMVC 2022) to serve as guidance for the generation. That works nicely! It creates images with similar semantic content, see the illustration for some example results.
The paper was accepted at CVPR 2023. A collaboration with University of Amsterdam, with PhD student David Zhang, professor Cees Snoek and others. Funded by NWO Efficient Deep Learning and TNO Appl.AI’s Scientific Exploration.

-
Embodied AI: handling domain gaps by language augmentations
We trained a robot to find certain objects (e.g., “sofa”) in simulated house environments. During training, each room has a certain wall color i.e., the living room has blue walls, kitchen red walls and the bedroom has green walls.
However, during testing the wall colors are different. Now the living room has green walls and the bedroom has blue walls. It turns out that the robot has learned a shortcut: it erroneously looks for the sofa in the blue bedroom, as it has simply learned to navigate towards a certain wall color.
This is a common problem: often simulators have limited variability and are not fully representative of the real world. Standard solutions are not practical: modifying the simulator is costly, standard image augmentation is not sufficient, and recent image editing techniques are not yet mature enough.
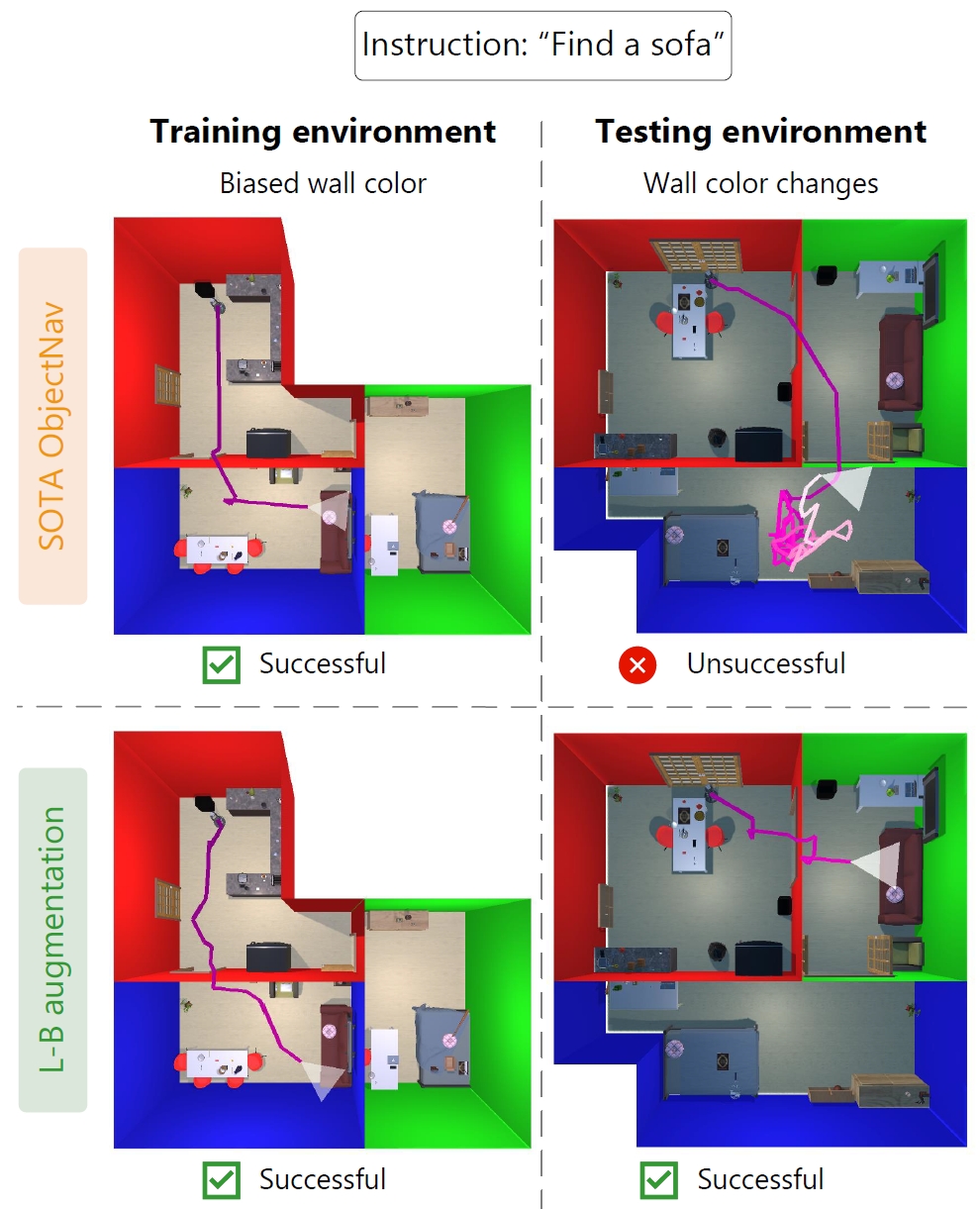
To solve this gap, we propose language-based (L-B) augmentation. The visual representations of the robot are based on a Vision-Language (V-L) model: CLIP. We leverage CLIP’s multimodal V-L space to augment the robot’s visual representation. By encoding text descriptions of variations of the dataset bias (e.g., ‘a blue wall’), using CLIP’s text encoder, we vary the robot’s visual representations during training. Now, the robot is unable to use the shortcut and correctly finds the object.
Kudos to our student Dennis who performed this very nice work.
-
Slot Attention with Optimal Transport
To discover objects without having an explicit model for them, Slot Attention is a very powerful technique. Yet, it may have trouble with separating objects (into different ‘slots’), when they are highly similar.
To improve separability, we build in a step to improve the discrimination of the learned features, by optimal transport. It helps to notice subtle differences.
Paper at NeurIPS workshop on Neuro Causal and Symbolic AI (nCSI), 2022 (Oral).
-
Self-Guided Diffusion
There is a revolution going on in the field of image generation. It was shown that such images get better when guiding them, e.g., with a textual description or semantic token from another classifier. We were curious whether we can guide them also with a self-supervised learning signal.

We use self-learned bounding boxes from another method to serve as guidance for the generation. That works nicely! It creates images with similar semantic content, see the illustration for some example results.
Paper at NeurIPS workshop on Self-Supervised Learning: Theory and Applications, 2022.
-
Reasoning with Missing Information
In crowded scenes, it is hard to keep track of objects. Sometimes they will be invisible because they are occluded. Meanwhile, something may happen, like a collision.
We devised a method that can extrapolate the tracks and reason whether a collision may happen. The camera feed is temporarily blocked, so for a moment the computer is blind. Still we can recover whether a collision is about to happen.
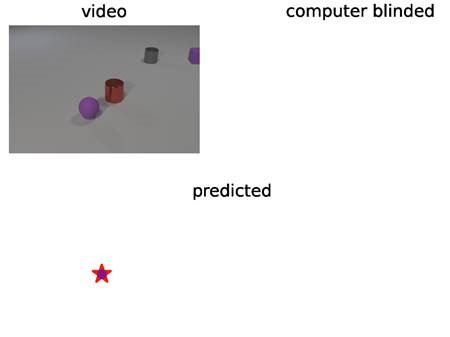
Please also see the demo in Videos.
-
Learning a Model from Stable Diffusion
There is a revolution going on in the field of image generation. Stable diffusion, Dall-E and Imagen make it possible to create images from a textual description. We were wondering whether such images may serve as a training set.

Well, it may work, but only for simple cases such as the blue and red jeeps and cars below. The problem with more advanced cases is that the images may be weird or implausable. Of course, you could have a human in the loop, to remove such problematic images.
-
Creating a Deep Learning Model without Labels using Semantics
Sometimes we do not have any images, let alone labeled images, for the particular class that we are interested in. But there are tons of labeled data about classes that are related. We re-use classifiers on those related classes to infer the class of interest.
For instance, localizing a Kart. Our method finds that Car, Motorbike and Skateboard are very related to Kart. We establish this by Optimal Transport. We reconstruct an object model (Faster R-CNN) for Kart by recombining the weights of Car, Motorbike and Skateboard.
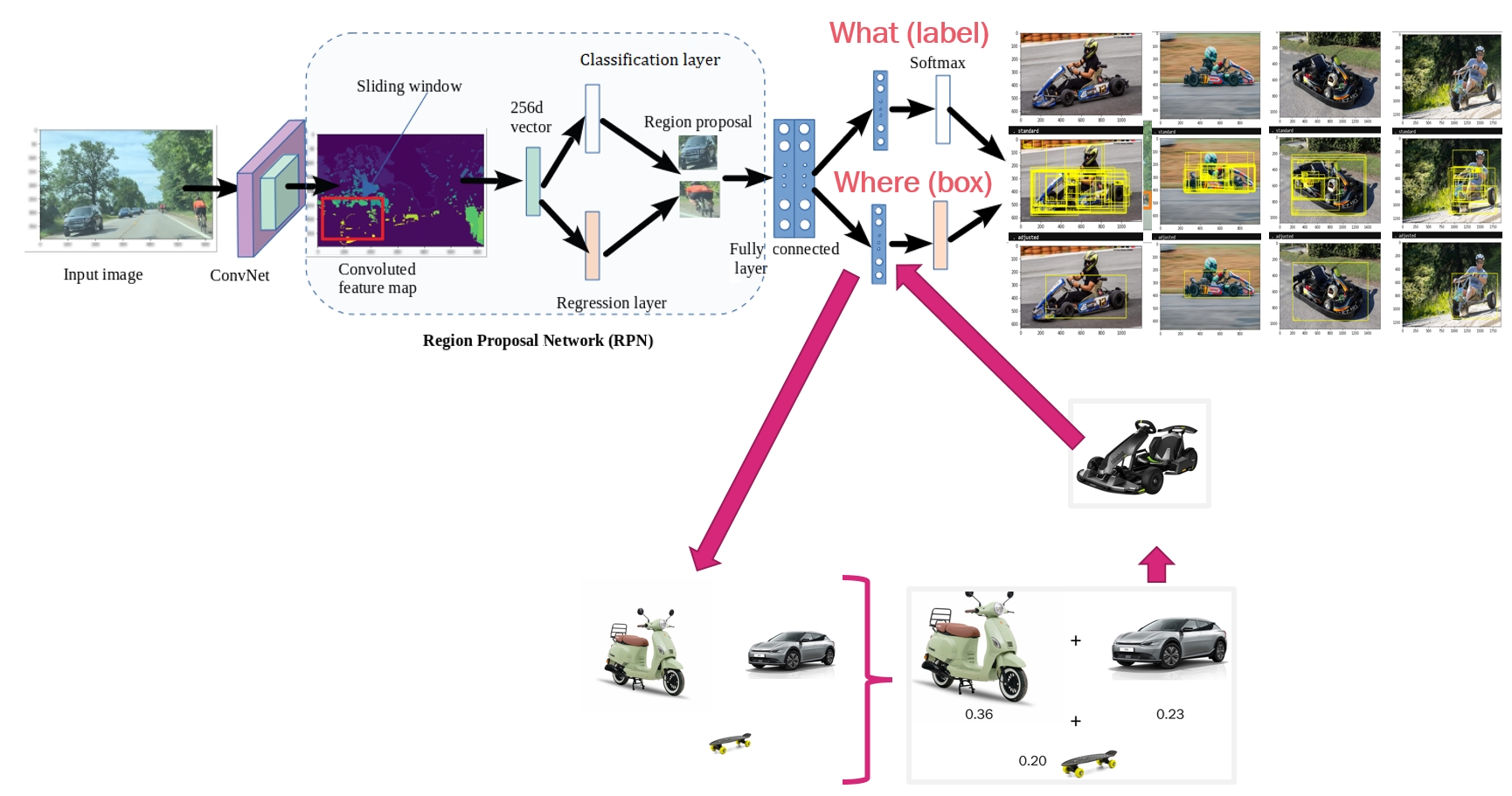
This makes it possible to localize related objects without having to label or learn anything. Work sponsored by DARPA Learning with Less Labels.
-
Searching for Images using Semantics
Suppose you are given a huge set of images. But you do not know what is in them. How do you start?
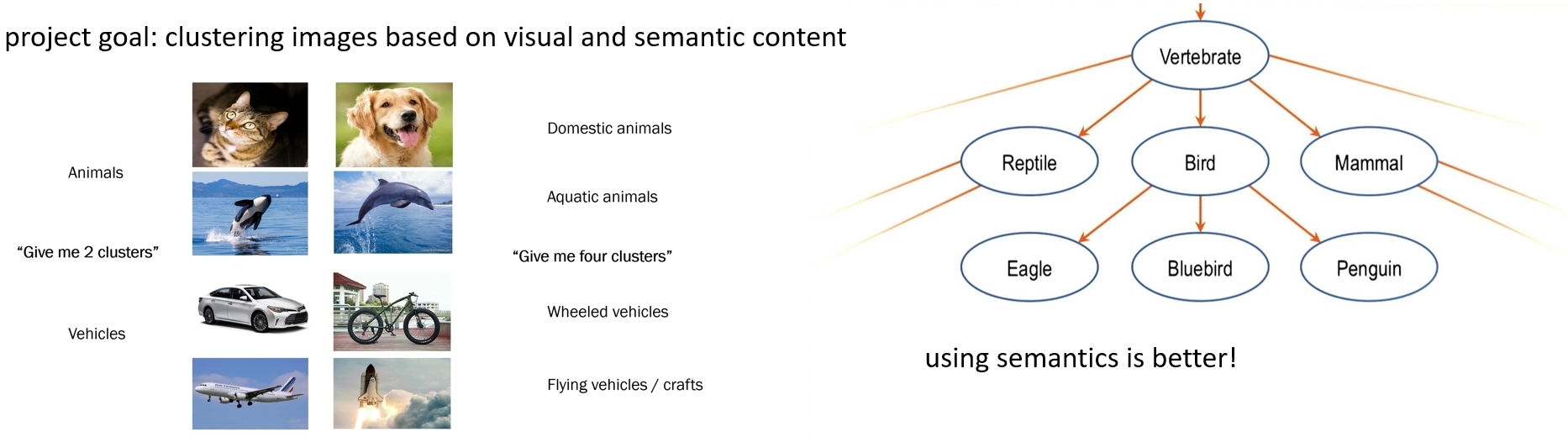
We have developed a method to cluster images and give each cluster a meaningful name. For each image, we assign an initial label from a large set of candidate words. We do this by a language-vision model: CLIP from OpenAI.
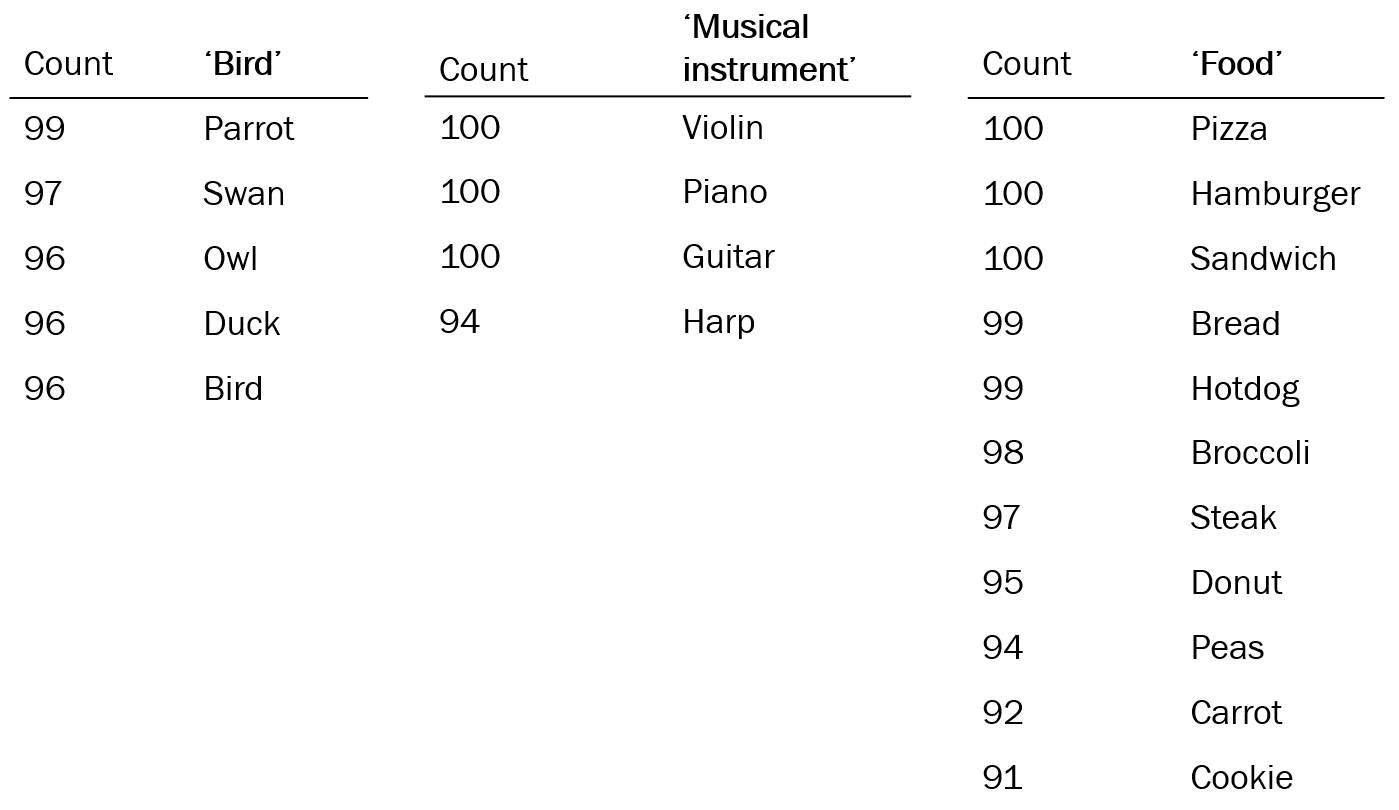
Next, we look for the word that best describes all images in the cluster. Possibly that could be a container name. We look into the coarse-to-fine hierarchy of all labels in the cluster, taken from Wordnet. In this way, we can assign Bird to a cluster containing images of Swans, Owls and Parrots.
-
Neuro-Symbolic Programming for Anomaly Detection
Our aim is to find an anomaly in an image, based on prior knowledge about the involved objects and their relations. A disadvantage of data-driven anomaly detection (statistical outlier models), is that they may produce anomalies that are not relevant at all.
In contrast, we specify anomalies in order to make sure that they are relevant. An overview of our method is shown below.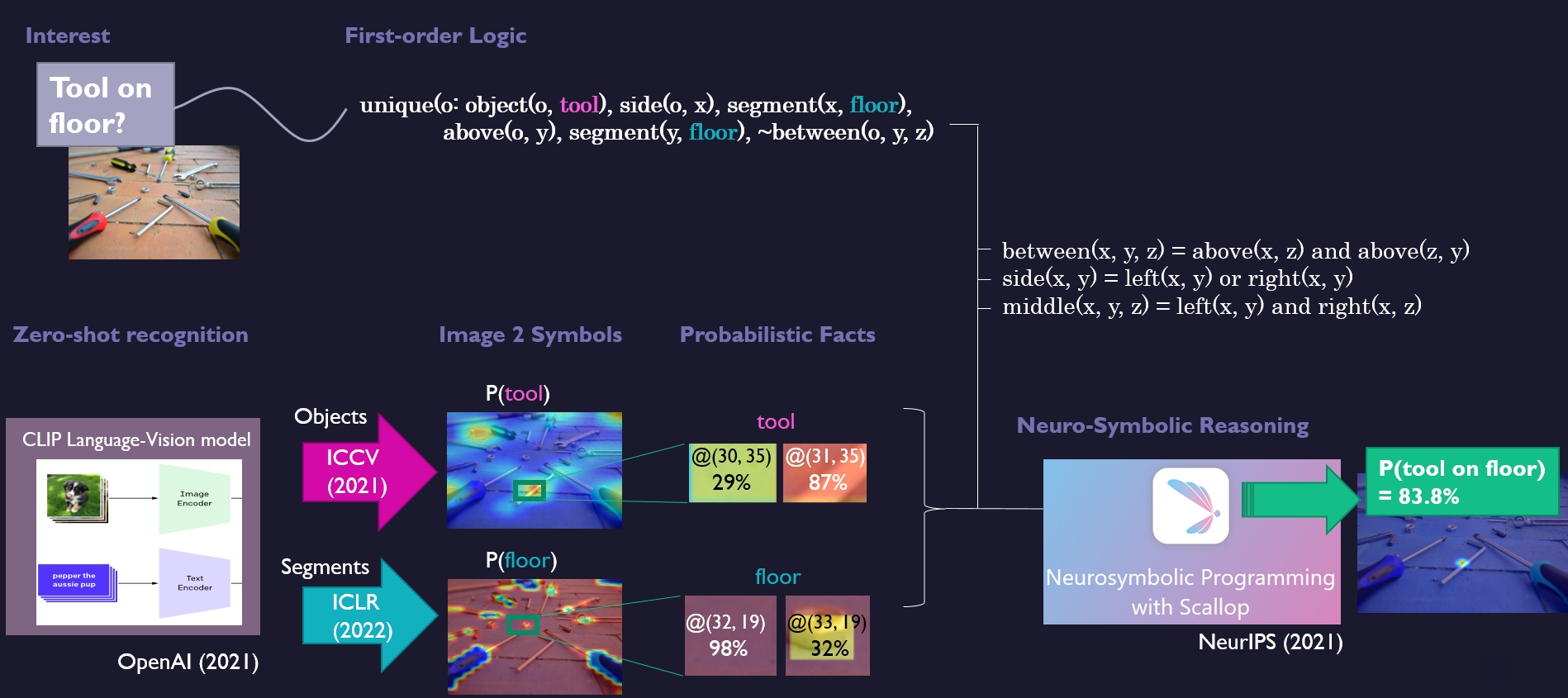
At the top, it shows how an anomaly such as ‘tool on floor’ is translated into symbolic predicates such as object(o, tool), segment(x, floor) and above(o, x). At the bottom left, the figure shows how the symbols from the predicates, such as ‘tool’ and ‘floor’, are measured from images by zero-shot language-vision models. These measurements are transformed into probabilistic facts, which are fed to the neuro-symbolic program in order to be validated against the logic (bottom right).
We presented our paper at IROS Probabilistic Robotics 2022 and we won the Best Paper award!
-
Unknown but Relevant?
Consider a robot operating in an open world, which sees novel classes during deployment. Or a police analyst who inspects a hard drive of photos and does not know beforehand what can be seen on them. Often, the user has a particular interest, e.g., vehicles.
But, the user may not know all possible types of vehicles beforehand, or, there are not yet images of them. There are common techniques to separate the novel classes from the known classes. We address the problem of further dividing the novel classes into relevant versus irrelevant novel classes.

For instance, the user who is interested in vehicles, has images of buses and shows these to the model, and wants to be informed when an image contains another vehicle type, while ignoring the non-vehicle objects. Our model will group various test images into known (buses), unknown relevant (vehicles) and unknown irrelevant (non-vehicles), see the figure below.
-
Multi-object Attribution
We want to reasoning about objects and their relationships. For instance, finding a woman who wears glasses next to a man who also wears glasses in the image below. With neuro-symbolic programming, we are able to find this combination.

Moreover, we can infer which objects in the image relate to which entities from the logical definitions (from the neuro-symbolic program). Here, the woman and the man, respectively.
This attribution is helpful for explainability of the hypothesis. It’s also helpful for further reasoning, e.g., to acquire additional information about these entities of interest.
-
NeurIPS paper accepted!
Do you want to boost image classification, long-tailed recognition, out-of-distribution and open-set recognition with single line of code?
Read our paper titled: Maximum Class Separation as Inductive Bias in One Matrix. For each class, it creates a vector that is maximally apart from all other classes, in a nice mathematical closed-form solution.
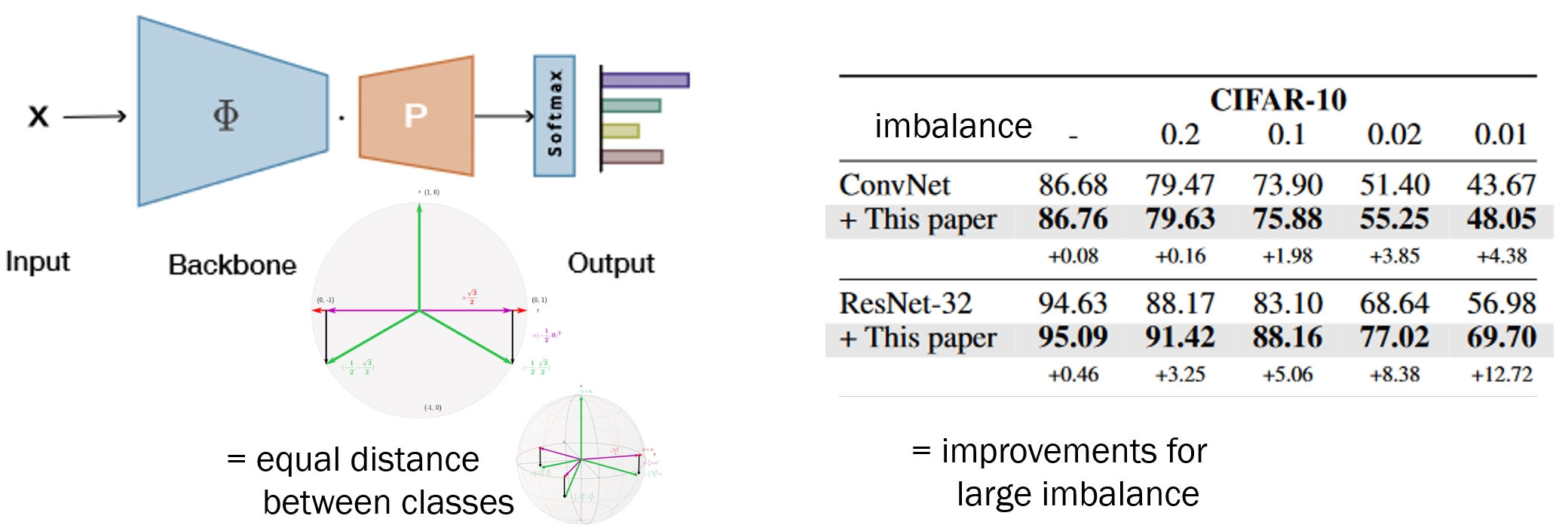
Wonderful collaboration with Tejaswi Kasarla, Pascal Mettes, Max van Spengler, Elise van der Pol and Rita Cucchiara!
-
Neuro-Symbolic Reasoning
Deep learning becomes more and more capable of detecting objects, classifying them, describing their attributes. This enables reasoning about such objects, their specifics, and relations!
For instance, see the photo of my research group at TNO. Can you find a woman standing next to a man, both wearing glasses?

First-order logic is able to describe this in a few lines of symbolic predicates. We recognize the symbols in the predicates via a language-vision model (CLIP). A neuro-symbolic program reasons about the logic and the recognized symbols with their probabilities.
This reasoning is probabilistic and multi-hypothesis with pruning. A crucial asset, if you have many objects that may sometimes be uncertain.
The result is highlighted. Pretty cool, right?
-
Maximum Separation between Classes
Maximizing the separation between classes constitutes a well-known inductive bias in machine learning and a pillar of many traditional algorithms. By default, deep networks are not equipped with this inductive bias and therefore many alternative solutions have been proposed through differential optimization. We propose a simple alternative: encoding maximum separation as an inductive bias in the network by adding one fixed matrix multiplication before computing the softmax activations.
Despite its simple nature, this one matrix multiplication provides real impact. We show that our proposal directly boosts classification, long-tailed recognition, out-of-distribution detection, and open-set recognition, from CIFAR to ImageNet.
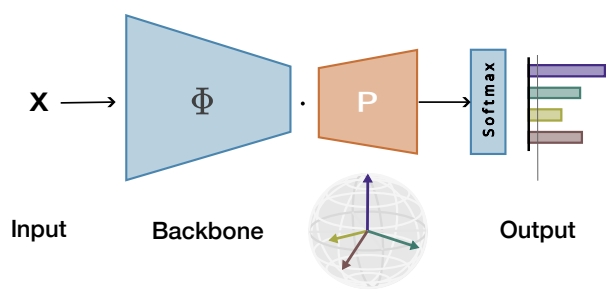
Work with Tejaswi Kasarla, Pascal Mettes, Max van Spengler, Elise van der Pol, Rita Cucchiara. Paper: https://arxiv.org/abs/2206.08704
-
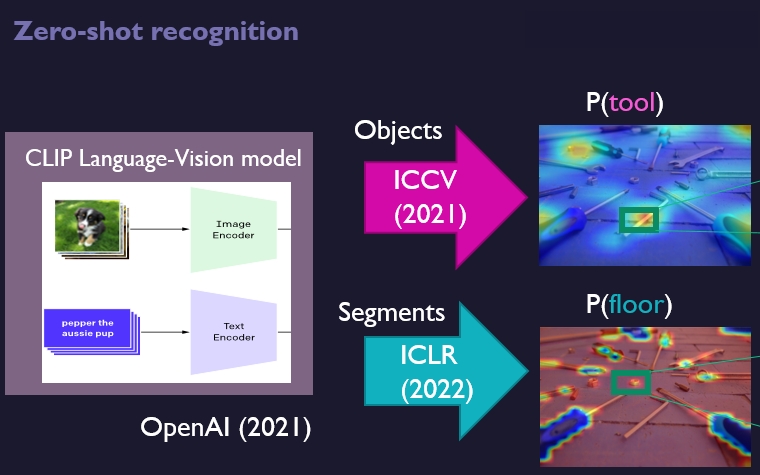
Using Language to Analyze Images
Recent models connect language and vision. That is very powerful for analysis of images. Language is also useful for generalization to new labels. We can now search through words in images. That doesn’t have to be exactly the right word, and that makes it widely applicable. CLIP (OpenAI), LiT and Flamingo are recent models that show great performance and promise for several use-cases:
-
Which word describes a picture? Example: Domainnet-Real consists of 345 classes (airplane, car, bus, etc.). For each image, CLIP can select the most likely of the 345 labels. This is done via text-image matching. The accuracy is 80%, which is quite impressive when you consider that random gives 0.3%.
-
Clustering a large set of images. CLIP can convert an image to a vector (embedding). This vector is very distinctive. Example: clustering Domainnet-Real, tens of thousands of images, with k-means, to 345 clusters, then 68% is correct.
-
Ranking of images. CLIP can be scored on how well a text search term matches an image. You can use that score to sort the images. In practice we see that images that come higher in the list actually match the searched term. Even if the search term is quite specific, such as ‘drone’ or ‘airport’.
-
-
Explainability of Predictions
I’m curious about deep learning and why it makes particular decisions.
Q1. How little of a picture does such a model need for a particular classification? A1: For an ambulance, you only need to see a piece of will and a red stripe (see attached video).
Q2. Which parts of a picture lead the model to a different classification? A2.1: An ambulance becomes more like a fire truck, if the red cross, the letters ‘ambulance’ and a few letters of ‘ambulance’ are not visible. A2.2: If the red stripes, the door, and the blue health symbol are not there, then an ambulance becomes the police car.
Check out the demo:
You see three types of vehicles: an ambulance, fire truck, or police car. For each picture, a part of the picture is first removed, as long as the classification remains the same (Q1). Later on, patches are removed to arrive at a different classification (Q2).
Key observations: (1) All these pictures were convertible to any other class! (2) Logos are important. (3) Specific details are important too, such as grill in the front, red lamp, or blue color. (4) Regularly, the predictions are based on very limited visual evidence.
For this experiment, an image was modeled as a bag of patches, encoded by a set prediction model. Modeling it as a set, enables us to remove patches (i.e., set elements) and still do predictions. The model can deal with a variable amounts of inputs.
-
How to select first labels for object detection?
Learning object detection models with very few labels, is possible due to ingenious few-shot techniques, and due to clever selection of images to be labeled. Few-shot techniques work with as few as 1 to 10 randomized labels per object class.
We are curious if performance of randomized label selection can be improved by selecting 1 to 10 labels per object class in a non-random manner. Our method selects images to be labeled first. It improves 25% compared to random image selection!
Below you see the first images, selected by our method, to be labeled. These are representative and the object is well visible yet not too large.

The paper is accepted for International Conference on Image Analysis Processing and presented next week. This research is part of DARPA Learning with Less Labels. More information when clicking on the post.
-
Multiset Prediction
Sets are everywhere: the objects in an image {car, person, traffic light}, the atoms in a molecule, etc. We research set prediction: how can a neural network output a set? This is not trivial, because sets can differ in size. The neural network needs to deal with variable-sized outputs. See our ICLR 2021 paper for an energy-based approach.
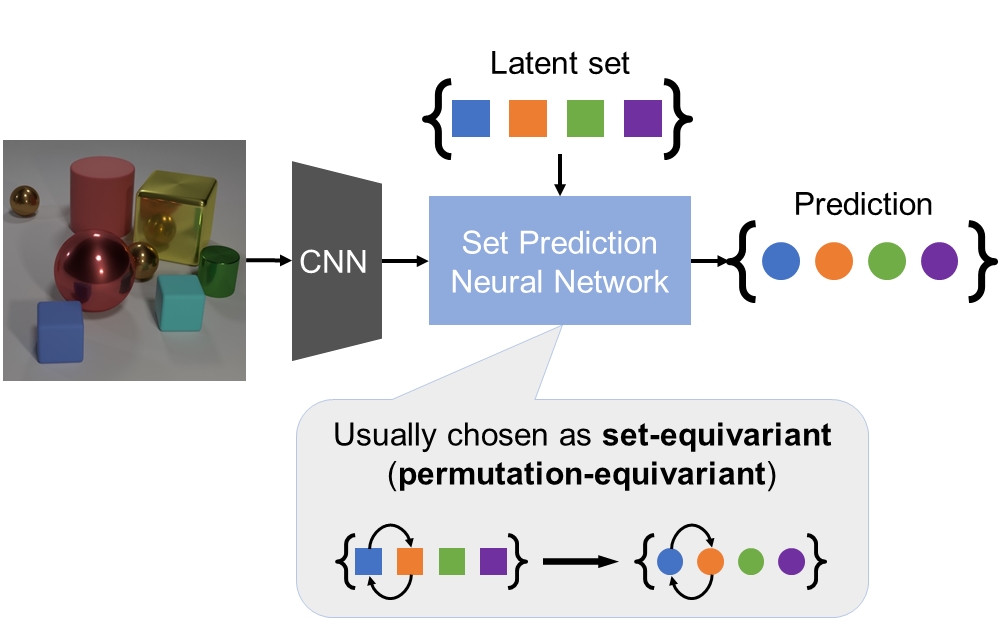
In our ICLR 2022 paper, we extend the method to deal with multisets. Contrary to sets, multisets can have multiple occurrences of a single element. For instance, {car, car, person, person, person, traffic light}. In multisets, elements may be identical, which poses a problem if we would like to get a different output for them. For instance, if we have {car, car} and we want to output the label and ordering {car-1, car-2}. Previous approaches are based on sets and cannot treat car-1 and car-2 differently.
We propose a method that can treat car-1 and car-2 differently, to output {car-1, car-2}. This essential ingredient is called multiset-equivariance. Published at ICLR 2022 and presented on May 25 2022.
This proves to be very helpful, not only to separate equal elements, but also similar elements. This property boosts the performance for both set and multiset prediction. Performance is favorable over Transformer and Slot Attention. In the example below, you see the prediction of objects and their properties, and how our method (last column) improves by refining iteratively (from left to right).
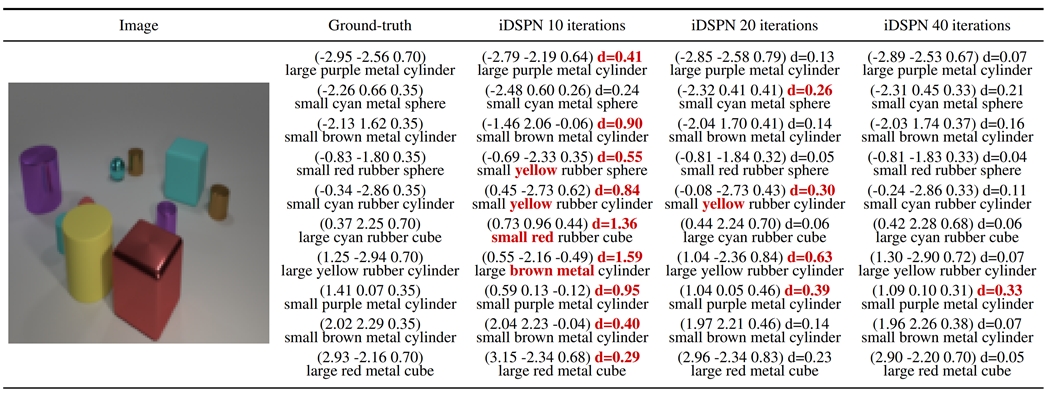
Part of NWO Efficient Deep Learning, co-sponsored by TNO Appl.AI.
-
Domain-specific Pretraining
We often retrain a deep learning model for a new domain and new classes. For instance, object detection in images that were recorded from above (overhead). These overhead images look very different from common datasets with (mostly) frontal images. Sometimes the classes are also different, such as swimming pools that become visible in overhead images.

For that purpose, we need to retrain the model. Preferably with as few labels as possible. Selecting a proximal dataset (labeled overhead images) is very helpful. We used DOTA 1.5, a big overhead dataset, as pretraining. We were able to improve the Pool-Car dataset accuracy from mAP=0.14 to mAP=0.33 with just 1 label per class.

Part of our research in DARPA Learning with Less Labels.
-
Visual Question Answering
Visual Question Answering (VQA) is a deep learning model that makes it possible to ask questions about an image in natural language. However, this often goes wrong in practice, especially with compound questions (“Is there a woman and a boy?”) and with questions that require understanding of the world (“a boy is a child”). Our method (Guided-VQA) extends VQA with such knowledge.
We have shown on the Visual Genome dataset that it leads to better answers. This technique allows us to search for objects for which we do not have an explicit detector, and combinations and relationships (“Is there a boy to the right of the woman?”).

Our idea is to decompose the compound queries, and to add common-sense to the resolving of such queries. We do so by an iterative, conditional refinement and contradiction removal. The refinement enables a coarse-to-fine questioning (leveraging taxonomic knowledge), whereas contradictions in the questioning are removed by logic. We coin our method ‘Guided-VQA’, because it incorporates guidance from external knowledge sources.
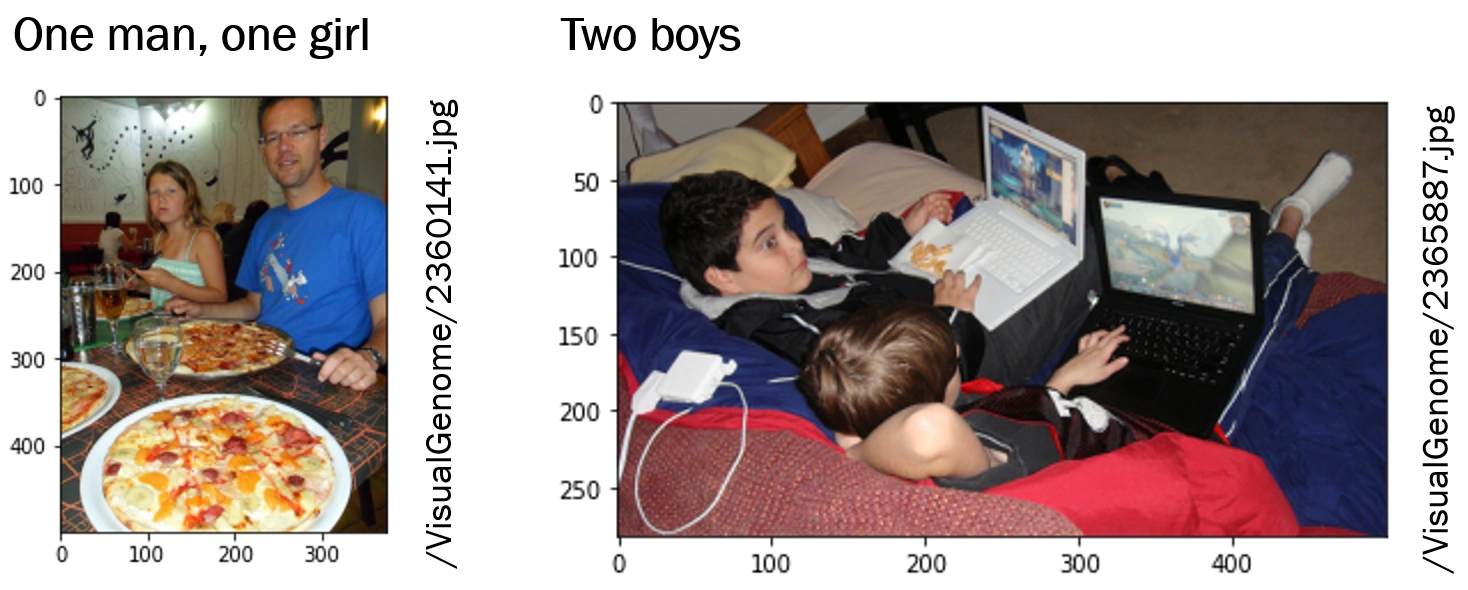
Published at International Conference on Image Analysis and Processing 2022.
(click on post to see more details)
-
Set Prediction by an Energy-based Model
Which celebrities have something in common? Please have a look at the top row in this image.

Which attributes do they share? It depends on how you look!
We developed a new deep learning model that is able to predict multiple answers. This is key to questions that are inherently ambiguous.
Each row in the attached image is one answer. In total, the model produces four answers. Blue indicates the celebrities who are not sharing two attributes. These four answers by the model are correct. Row 1: man and no beard. Row 2: man and glasses. Row 3: man and bold. Row 4: bold and glasses.
Paper at ICLR ‘21 with David Zhang and Cees Snoek (University of Amsterdam). More information when clicking on the post.
-
Out of distribution
Deep Learning is a great tool. But, one of its problems is that it’s overly optimistic: too high confidences for unknown classes. That’s a problem in an open world where new classes may be encountered.
See the unknown fruit below. Standard deep learning (left) is shockingly certain that it is pear (which it not the case). We extended a standard model with a notion of uncertainty: it says the unknown does not look like the known classes (right).
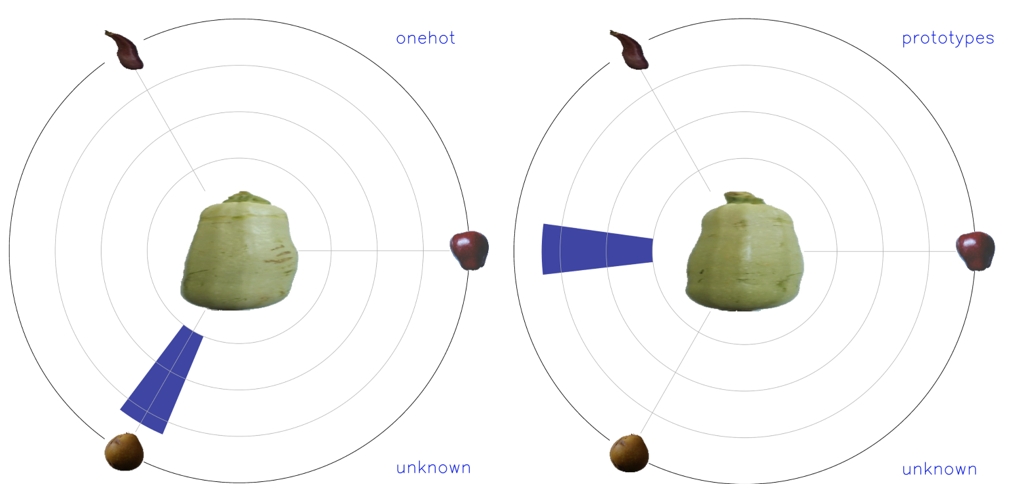
At the Videos section, you can find more examples.
Our model is an Equidistant Hyperspherical Prototype Network. The paper was accepted at NeurIPS, at a workshop about uncertainty in decision making. It is a collaboration with Pascal Mettes from the University of Amsterdam.
The prototypes are almost for free. This model has the same backbone network, while requiring less weights for the classifier head. It just requires 5 additional lines of Python code for the prototypes and the cosine loss.
-
Deployable Decision Making in Embodied Systems
In December, I was at the NeurIPS Workshop on Deployable Decision Making in Embodied Systems, to present our paper about modeling uncertainty in deep learning.
This was our poster:

Great talks by (and panel discussions with) experts in robotics, vision, machine learning (DeepMind, MIT, Columbia, EFPL, Boeing, etc.).
The focus was robustness of systems that have machine learning components. Key questions were: how to safely learn models & how to safely deal with model predictions?
Boeing mentioned that they only consider a machine learning component for the bigger system, if besides its output (e.g., a label with a confidence) it also produces a second output indicating its competence for the current image or object. Interesting thought!
The workshop website is here.
-
Uncertainty of Predictions
Knowing the uncertainty of a prediction by a deep learning model is key, if you want to base decisions on it. Especially in an open world, where not everything can be controlled or known beforehand.
We have modeled prototypes that are maximally apart, so the unknown samples have maximum likelihood of falling in the in-between spaces. Indeed, out-of-distribution samples have a larger distance to the prototypes. The distance is a good proxy of uncertainty.
This work was published in NeurIPS workshop on Deployable Decision Making (DDM). The illustration shows image segmentation and the uncertainty of the predictions per pixel.

This research is part of TNO’s Appl.AI program. It is a collaboration of Intelligent Imaging and Automotive department (Helmond).
-
Hypergraph Prediction
Predicting graphs is becoming popular, as many problems are structural and can be expressed as a graph. For instance, relations between objects in a scene. Often, the relations are multi-way, beyond standard graphs with edges that connect two nodes. Connecting multiple nodes requires hypergraph prediction. We propose to do this in a recurrent way, at each step refining the predicted hypergraph.

-
Using domain knowledge to improve artificial intelligence
On Friday, I gave a talk at the European Big Data Forum, for 135 people. My talk was about using domain knowledge to improve AI:
One of the challenges in applying artificial intelligence, and deep learning in particular, is a lack of representative data and/or labels. In some extreme cases, no labeled data samples are available at all. Besides the problem of data, applied models often have a lack of understanding the application’s context. Our research focuses on bridging that gap, such that deep learning can be applied with few labels, and that learned models have more context awareness.

In this talk, I will show why this is important, and some approaches that may solve some of these issues. A key topic is to leverage domain or expert knowledge in machine learning. This offers a step towards more robust and aware applications of artificial intelligence.
-
Using knowledge and selecting labels in DL: 2 papers accepted
Our two papers got accepted at International Conference on Image Analysis and Processing.
One paper is about Visual Question Answering (VQA). We consider image interpretation by asking textual questions. We extended VQA with knowledge (taxonomy), called Guided-VQA, to enable coarse-to-fine questions. This research is part of the Appl.AI SNOW project.
The other paper is about DARPA Learning with Less Labels. We propose to select particular images for labeling objects. We show that such selection is better for object detection when having very few labels. We consider only 1-10 labels per class, while standard is to have hundreds per class. For many practical applications few labels are available.
Soon more information follows.
-
Uncertainty Quantification
Quantifying uncertainty is a key capability for (semi)autonomous systems, in order to understand when the model is uncertain, e.g., when it encounters something unknown (out of distribution, OOD). For instance, robot SPOT is in a place that it does not know, so it can invoke assistance or go in safe mode.
Our experiment is illustrated below: three categories of places are known (Home, Work, Public places), and, one category is unknown: Shops (seen only at test time).

We have researched prototypes for this purpose. The paper is published at a NeurIPS workshop about uncertainty.
Prototypes are a set of vector representations, one for each class. We propose equidistant hyperspherical prototypes that are maximally separated, such that OOD samples fall in between. We show that in practice this indeed happens. The distance to such a prototype is a good quantification of uncertainty.
The figure shows an example of 4 classes and their prototype in 3D, with learned projections of samples (dots) and the samples that are considered to be outliers (squares).
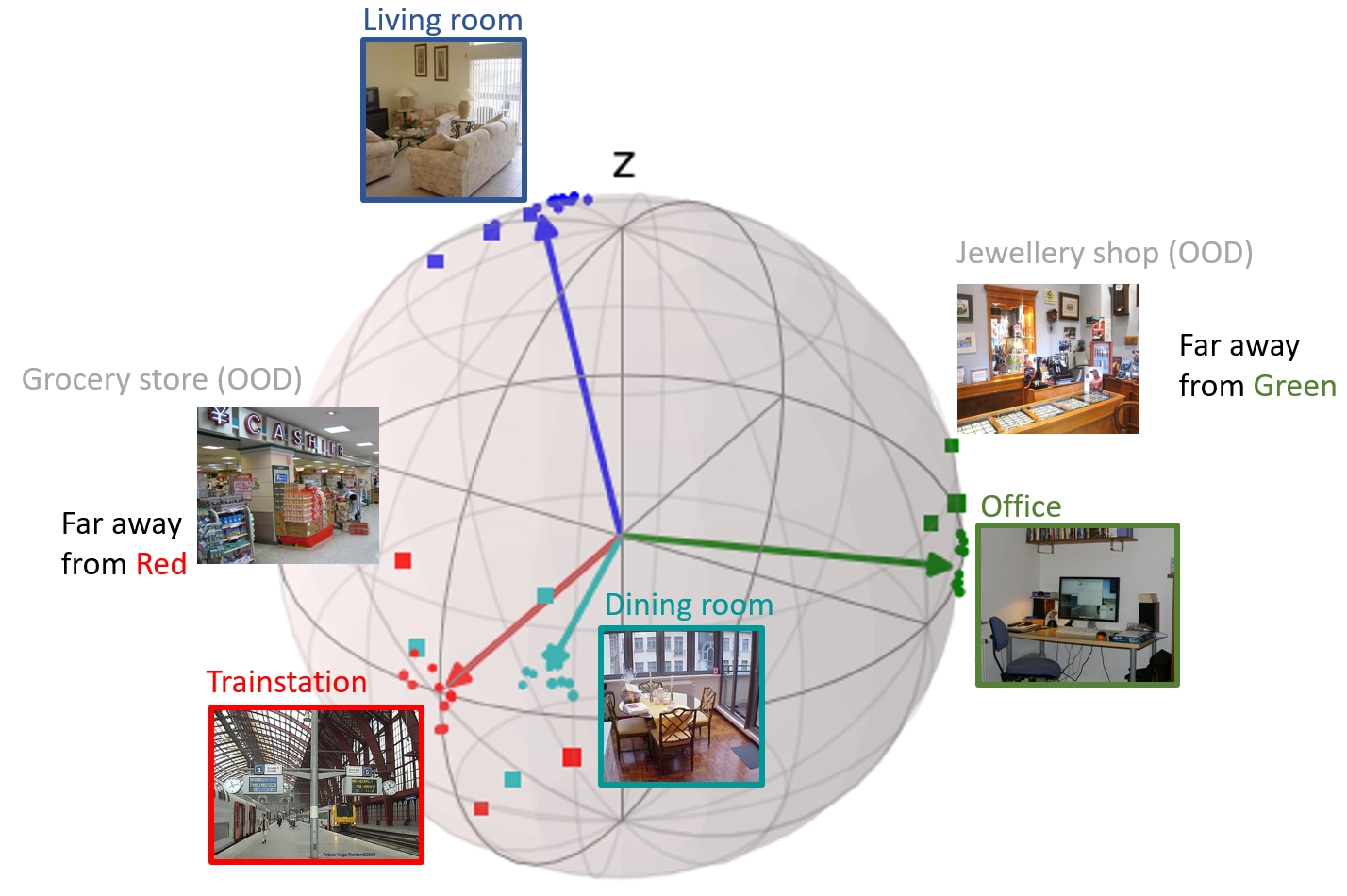
-
Our paper is accepted at NeurIPS!
We want Deep Learning models that generalize beyond previous observations. Someone who has never seen a zebra before, could nevertheless recognize one when we tell them it looks like a horse with black and white stripes. Standard Deep Learning cannot do that.
In DARPA’s Learning with Less Labels, together with University of Twente, we have developed the ProtoProp model. Our model is compositional: it recombines earlier knowledge.
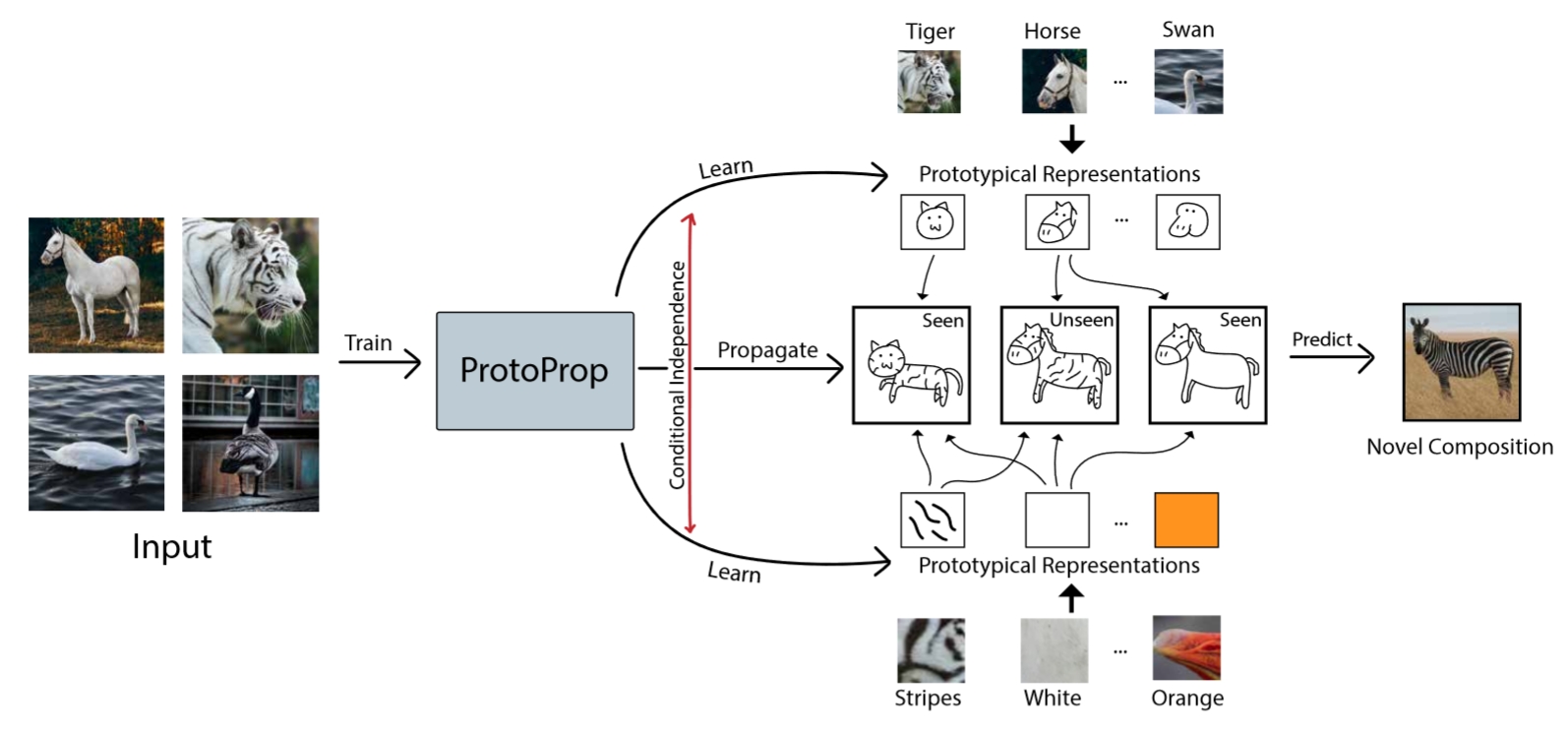
The paper is accepted at NeurIPS.
(read more by clicking the post)
-
Scenes as Sets of Objects
In one of our projects, a robot is searching rooms for persons, in a search and rescue setting. The person may have fallen behind a couch, and therefore invisible. Can we infer whether it is likely that a person is in the current room, based on the observed objects? Quite well, see the illustrations below!
One challenge is that the number of objects varies from scene to scene. That is why we need to model sets, read more by clicking on this post.

-
Appl.AI @ TNO
At TNO, there are many research projects centered around Artificial Intelligence and Deep Learning, from Vision and NLP to Knowledge Graphs. The large research program for Applied AI is called Appl.AI. Appl.AI has a website portal where you can find more information. Hopefully it’s a useful overview and resource!
-
Active Vision for Robotics
The cool thing about a robot is that it can act to improve its performance. For instance, by getting closer to the object, more details can be perceived, thereby resolving uncertainty. This demo video shows that the robot successfully approaches and confirms the objects of interest, and quickly abandons the other irrelevant objects.
The robot’s goal is to find human dolls. Sometimes the object is not a doll, but a transformer toy. At first, it is always uncertain, because the object is very small. It decides to get closer to resolve the uncertainty. More detail is helpful to resolve what the object is.
-
Robotics and Deep Learning with SPOT
Our research on robotics with SPOT was in the newspaper (Telegraaf). The goal is to provide SPOT with more autonomy via context awareness. As part of this awareness, we look into visual question answering (find me the room with a boy and a girl) and objects with part attributes (find the girl with the green sweater).

-
Compositionality of objects and attributes
Humans are good at compositional zero-shot reasoning; Someone who has never seen a zebra before could nevertheless recognize one when we tell them it looks like a horse with black and white stripes.
Machine learning systems have difficulty with compositionality. We propose a method that uses a graph that captures knowledge about compositions of objects and their attributes, and learn to propagate through the graph, such that unseen classes can be recognized based on their composition of known attributes.
-
Zero-shot Object Localization
Detecting objects is important and works very well. But, to learn a model, many images are required. We research techniques to learn with less labeled images. To the extreme: zero labels.

Our approach is to learn the object by its known parts. For instance, a bicycle composed of a frame, saddle, steer and wheels.
Because there can be multiple bicycles in the scene, the algorithm needs to reason about the parts and their possible compositions. To that end, we developed a multiple hypotheses method that takes into account multiple criteria about parts, such as their overlaps and relative size.
-
Interactive Video Exploration
Looking for particular concepts in a large set of videos or images is very relevant with today’s amounts of data. A correct way of visualizing by plotting similar instances close together, really depends on what you’re looking for. When searching for a particular person, the similarity should be based on people’s appearances, whereas for activities it should be based on motion patterns.
-
NATO Award
For my contribution to a NATO research group (see post below), I received this beautiful award!

-
Content-based Multimedia Analytics
For the last years, I was part of a NATO research group about multimedia analytics. The goal was to invent new ways of making use of multiple modalities.
Our focus was on social media (text, images) and videos. For this work, we received an Excellence Award from NATO.

-
Learning from Simulation and Games
Sometimes images of objects-of-interest are not available. For instance, rare objects such as a tank. Can we train an object detection model on simulated images? Yes, we can! A model trained on the game GTA-5 detected these objects in YouTube footage.

-
Competence in (un)known environments
A video of our paper at ACM/IEEE Human Robot Interaction is now available on YouTube. The topic of the paper is: ‘Is my AI competent here?’ - for robots that move around and may get into unexpected situations where learned models may fail.

-
Learn objects with just one label?
Can we learn how to detect an object if we just have one label? This is the key question that we are trying to solve in DARPA Learning with Less Labels program. During the first year of the program, we performed well on an international benchmark.

Other teams are key players in AI in USA (e.g., Berkeley) and Australia. It is very nice to collaborate with and learn from these other teams.
-
Localizing Aggression in Videos
Interpretation of human behavior from video, is essential for human-machine interaction, public safety and more. Together with the national police and the city of Arnhem, we researched the feasibility of aggression detection during nightlife.

-
Periodic Motion in Video
I was honored to be part of the PhD committee of Tom Runia, about periodic motion in video. At the University of Amsterdam, with promotors prof. Cees Snoek and Arnold Smeulders. Periodic motion is important as it appears in many activities such as sports, working and cooking.

-
Transformers for Vision
Transformers are becoming popular for vision tasks, including image classification, object detection and video classification. In this presentation, I explain Transformers and how they are applied to Vision tasks.
-
Detecting small objects by their motion
When objects appear very small in images, standard object detection has difficulties. This is because it relies on the object’s texture, which becomes invisible at such small scales. Detecting small objects based on their motion is a better alternative. See the image below, where a standard detector fails (top row) and a motion-based detector (bottom row) detects the small objects.

-
Patent granted: Sequence Finder
The innovation is called Sequence Finder. This algorithm finds temporal patterns (e.g., making a coffee) by propagating confidences (not binary!) about shorter-term activities (e.g., taking cup, pooring milk, turning on coffee machine).

-
AI says: am I competent here?
AI agents such as robots are often not aware of their own competence under varying situations. Yet it is critically important to know whether the AI can be trusted for the current situation. We propose a method that enables a robot to assess the competence of its AI model.
-
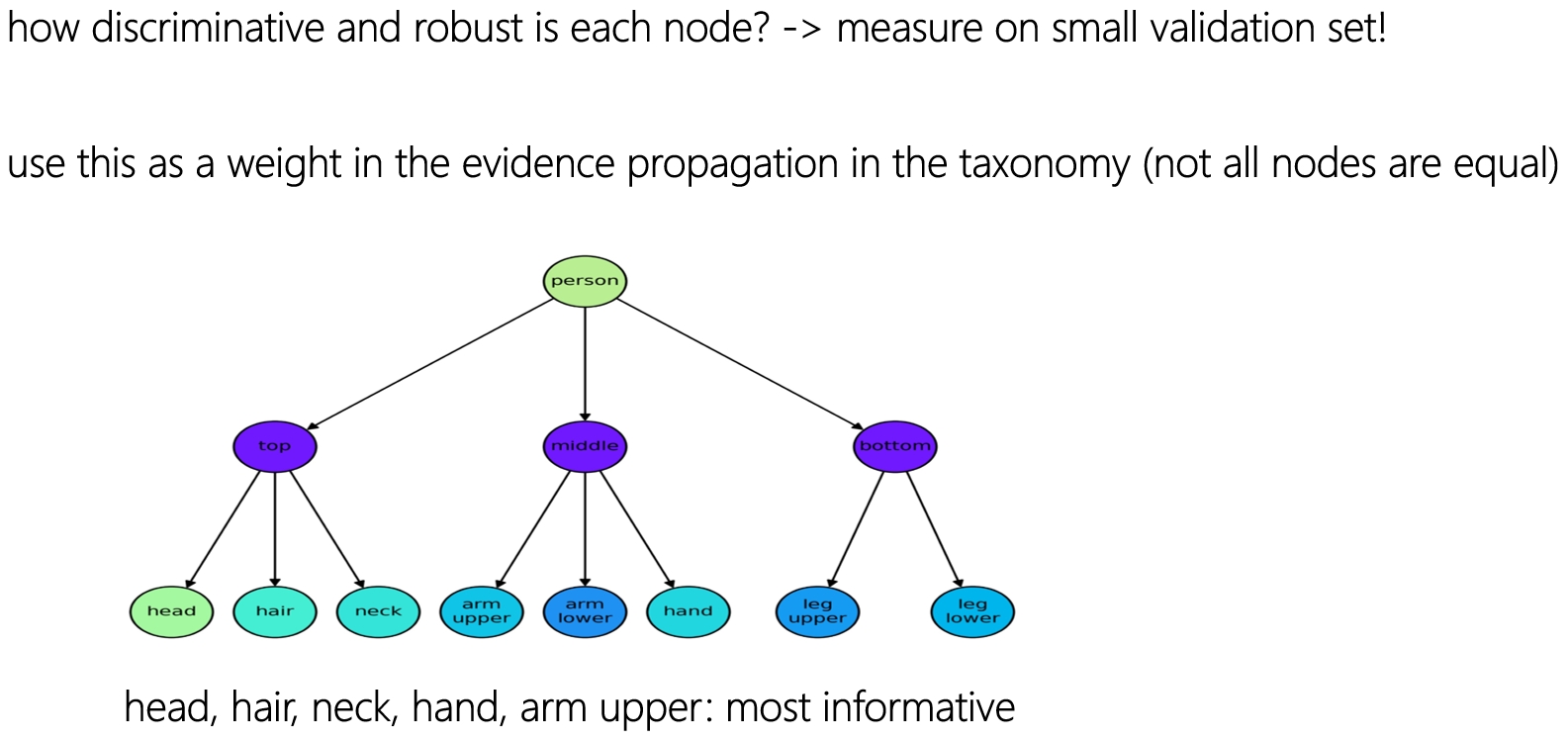
Weighting evidence by thrustworthiness
Our aim is to increase the autonomy of the SPOT robot. Our research covers perception, planning and self management. For perception, one of the challenges is to understand objects, even when they are novel or not seen before. Novel objects are detected by recognizing and combining their parts.
But not all parts are equally discriminative or robust. This post is about combining evidence in a more principled way, by taking the evidence for each part into account.
The coloring of the nodes in the part-hierarchy shows that some parts are more thrustworthy (e.g., head) than others (e.g., lower arm).
-
Novel object detection by a hierarchy of known parts
Imagine a robot that can help with search and rescue tasks, to find victims, in situations that are dangerous to humans. In the SNOW project, we aim to endow the SPOT robot dog with such a capability. Key is to recognize victims, even if they are only partially visible. For instance, a person may have fallen behind a bed. This perception is done by a SNOW algorithm, called HITCH (Hierarchical Task-specific Characterization).
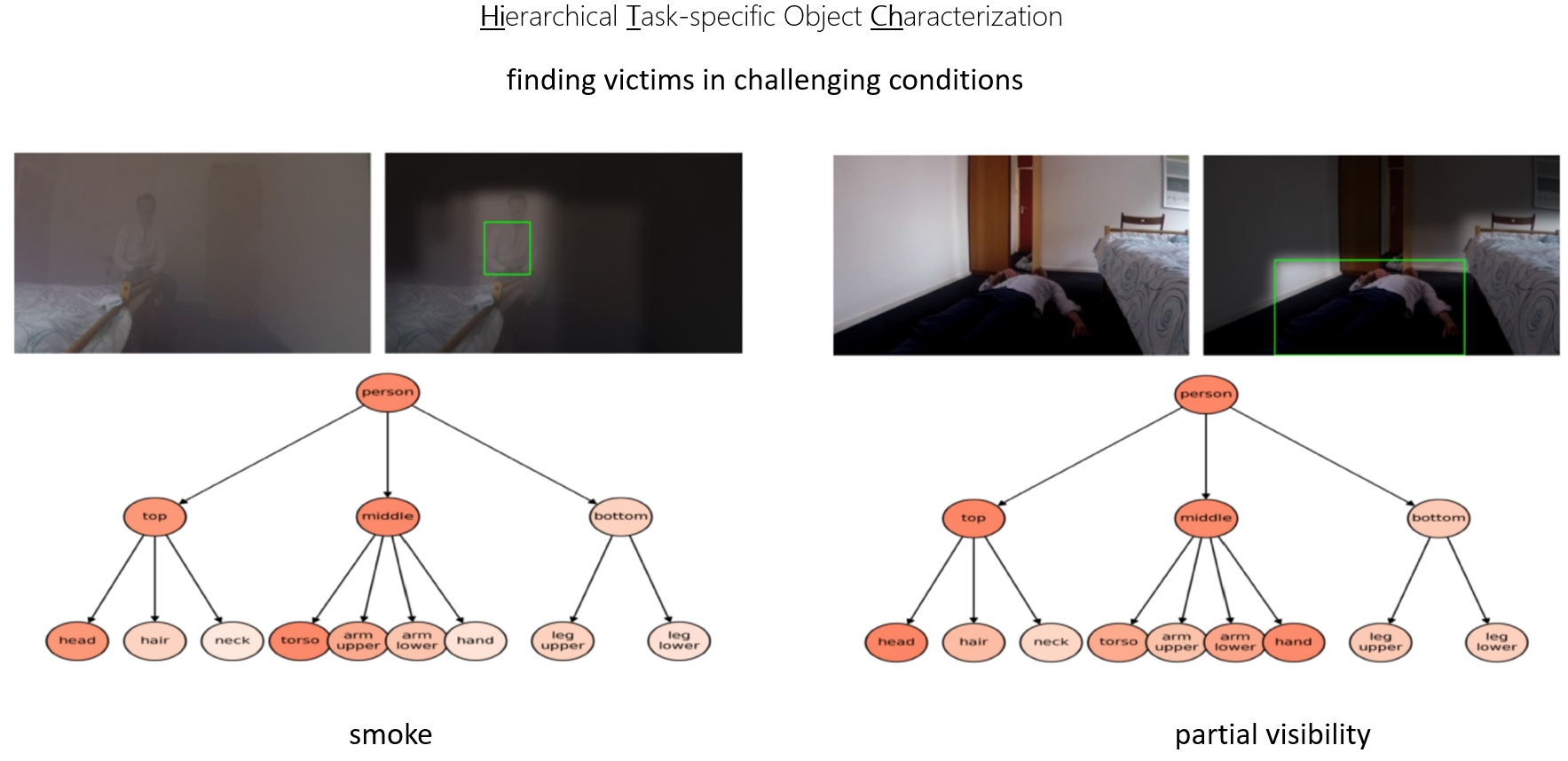
-
Novelties and Anomalies as Outliers
Spotting the statistical outliers is relevant for detection of novelties (e.g., a yet unknown object) and anomalies (e.g., a production error).
Suppose that you have only seen images of cars. Cars are the inliers. Now you want to know when objects are different from cars. These are the outliers.

-
Zero-shot object recognition
Suppose that you want to recognize an object, but you don’t have any images of that object. Standard deep learning will fail without training samples. Now suppose that you have knowledge about its parts. Often, images of (everyday) parts are available. We have developed a technique, ZERO, to recognize unseen objects by analyzing its parts.

-
Spot What Matters
Our paper ‘Spot What Matters: Learning Context Using Graph Convolutional Networks for Weakly-Supervised Action Detection’, is accepted for the International Workshop on Deep Learning for Human-Centric Activity Understanding (part of International Conference on Pattern Recognition).
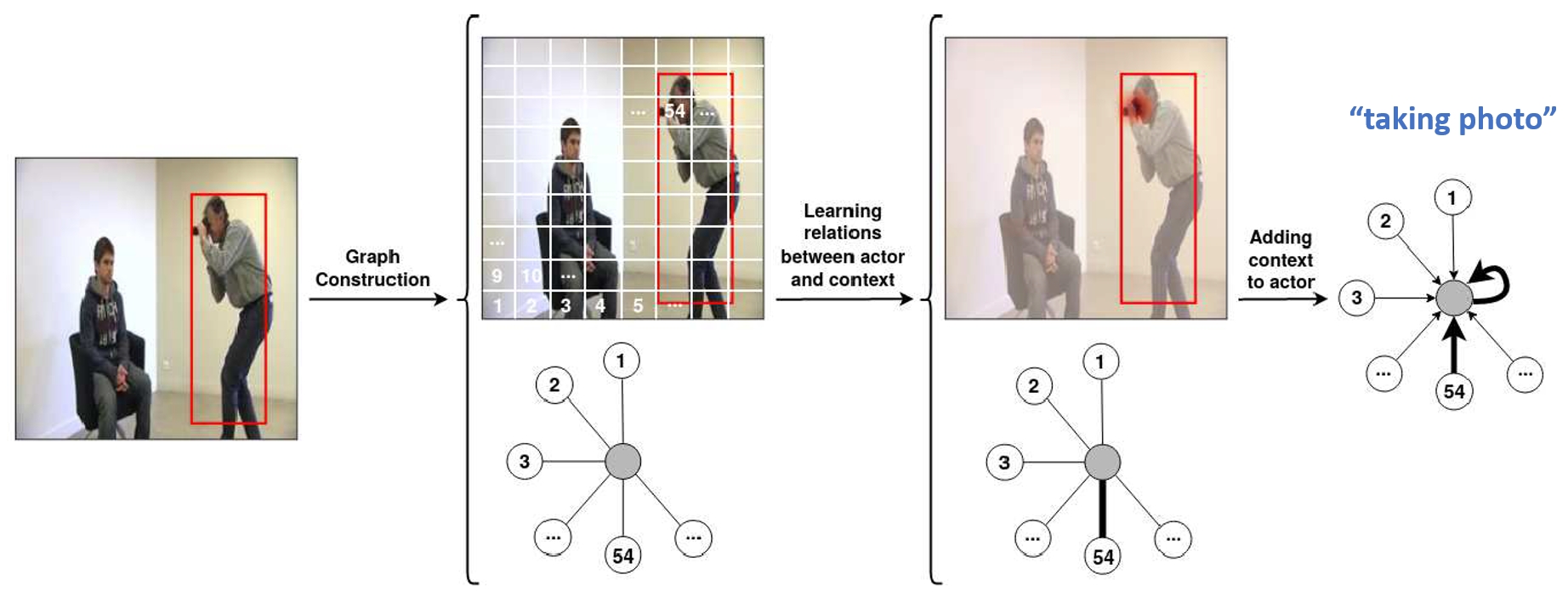
-
Paper accepted at ICLR 2021
Our paper on Set Prediction was accepted at International Conference on Learning Representations (ICLR 2021). This research is about predicting sets such as reconstructing point clouds or identifying the relevant subset from a large set of samples.
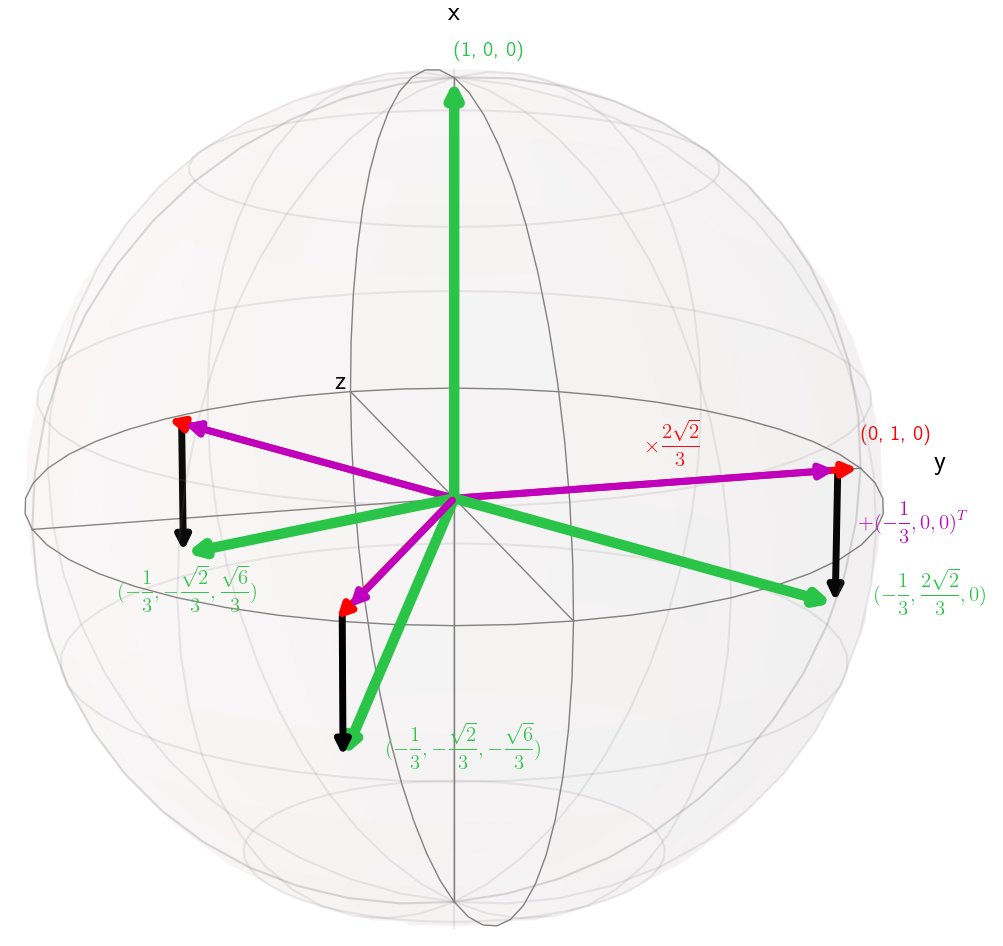

subscribe via RSS