Using Language to Analyze Images
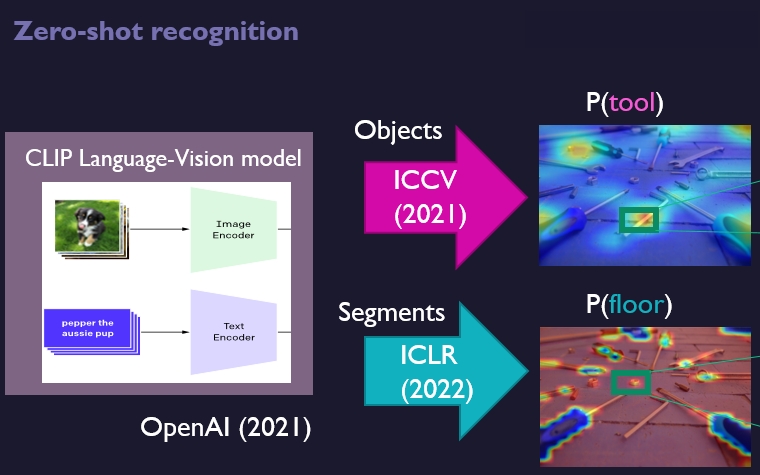
Recent models connect language and vision. That is very powerful for analysis of images. Language is also useful for generalization to new labels. We can now search through words in images. That doesn’t have to be exactly the right word, and that makes it widely applicable. CLIP (OpenAI), LiT and Flamingo are recent models that show great performance and promise for several use-cases:
-
Which word describes a picture? Example: Domainnet-Real consists of 345 classes (airplane, car, bus, etc.). For each image, CLIP can select the most likely of the 345 labels. This is done via text-image matching. The accuracy is 80%, which is quite impressive when you consider that random gives 0.3%.
-
Clustering a large set of images. CLIP can convert an image to a vector (embedding). This vector is very distinctive. Example: clustering Domainnet-Real, tens of thousands of images, with k-means, to 345 clusters, then 68% is correct.
-
Ranking of images. CLIP can be scored on how well a text search term matches an image. You can use that score to sort the images. In practice we see that images that come higher in the list actually match the searched term. Even if the search term is quite specific, such as ‘drone’ or ‘airport’.