Embodied AI: handling domain gaps by language augmentations
We trained a robot to find certain objects (e.g., “sofa”) in simulated house environments. During training, each room has a certain wall color i.e., the living room has blue walls, kitchen red walls and the bedroom has green walls.
However, during testing the wall colors are different. Now the living room has green walls and the bedroom has blue walls. It turns out that the robot has learned a shortcut: it erroneously looks for the sofa in the blue bedroom, as it has simply learned to navigate towards a certain wall color.
This is a common problem: often simulators have limited variability and are not fully representative of the real world. Standard solutions are not practical: modifying the simulator is costly, standard image augmentation is not sufficient, and recent image editing techniques are not yet mature enough.
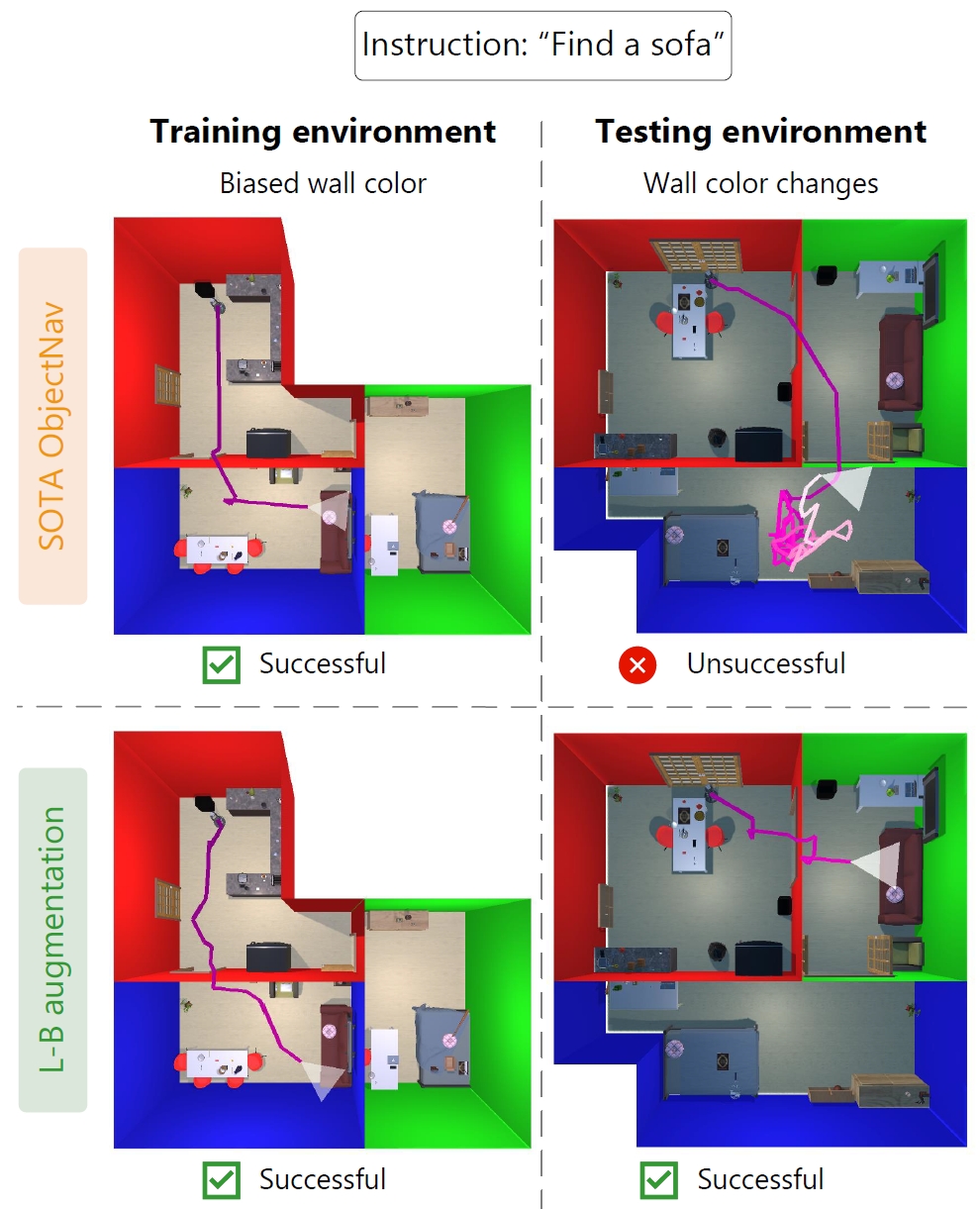
To solve this gap, we propose language-based (L-B) augmentation. The visual representations of the robot are based on a Vision-Language (V-L) model: CLIP. We leverage CLIP’s multimodal V-L space to augment the robot’s visual representation. By encoding text descriptions of variations of the dataset bias (e.g., ‘a blue wall’), using CLIP’s text encoder, we vary the robot’s visual representations during training. Now, the robot is unable to use the shortcut and correctly finds the object.
Kudos to our student Dennis who performed this very nice work.