Better LLMs have a better understanding of the Visual World
Ever wondered if better LLMs actually have a better understanding of the visual world? As it turns out, they do! We find: an LLM’s lingual performance correlates with zero-shot performance in a CLIP-like case when using that LLM to encode the text.
To test this rigorously, we build the Visual Text Representation benchmark (ViTerB) in which a frozen vision and frozen text encoder are trained CLIP-like manner with controlled paired data - s.t. we measure the true generalisation that comes from language understanding.
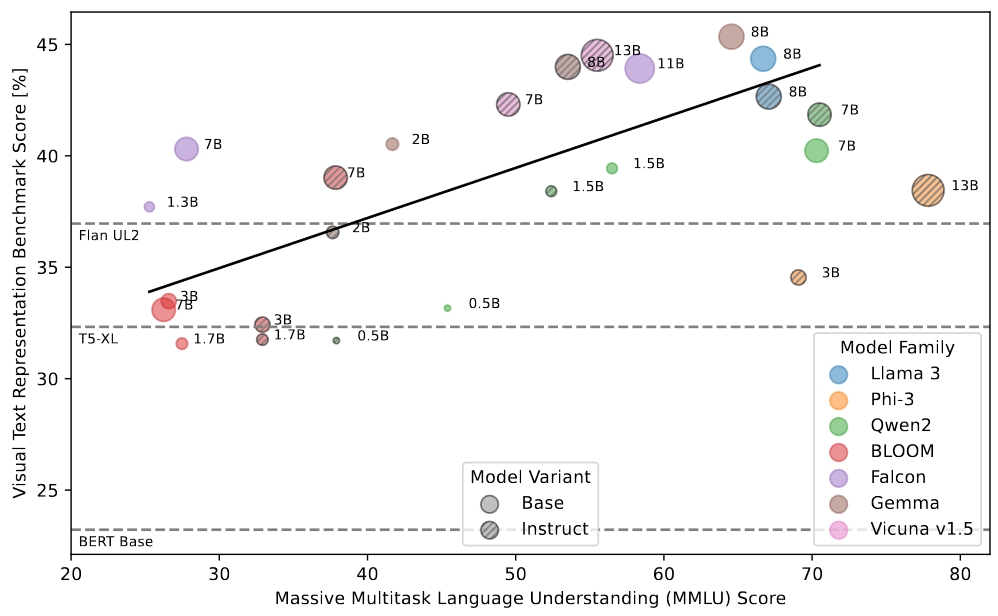
Surprisingly, we find that decoder-only LLMs actually give great representations! Better than T5, UL2 etc. So we make a new method that freezes not only vision encoder (e.g. LiT) but also uses frozen LLM decoders, we call it ShareLock.

We also train our method on CC3M and CC12M. Because of the frozen and precomputed features, training is done in 2h (and even precomputing only takes ~8h) on a single A100 GPU. Performance is also very good!
