Spot What Matters
Our paper ‘Spot What Matters: Learning Context Using Graph Convolutional Networks for Weakly-Supervised Action Detection’, is accepted for the International Workshop on Deep Learning for Human-Centric Activity Understanding (part of International Conference on Pattern Recognition).
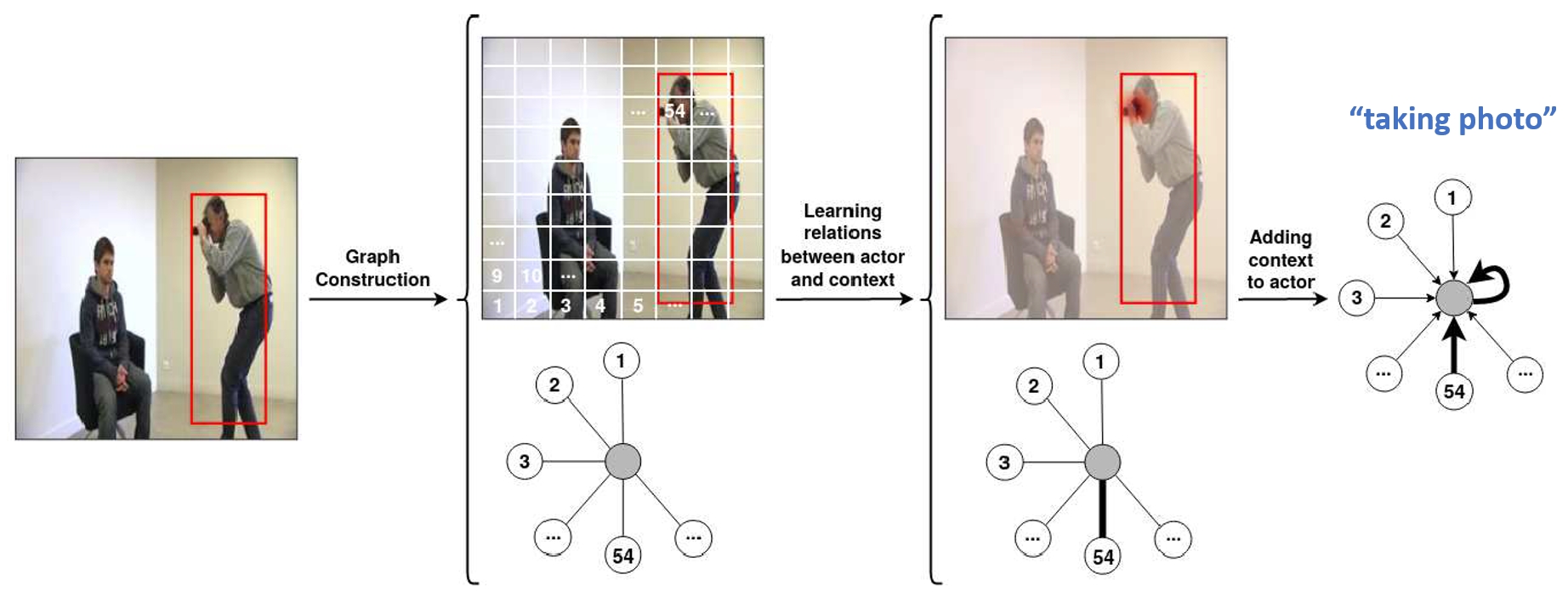
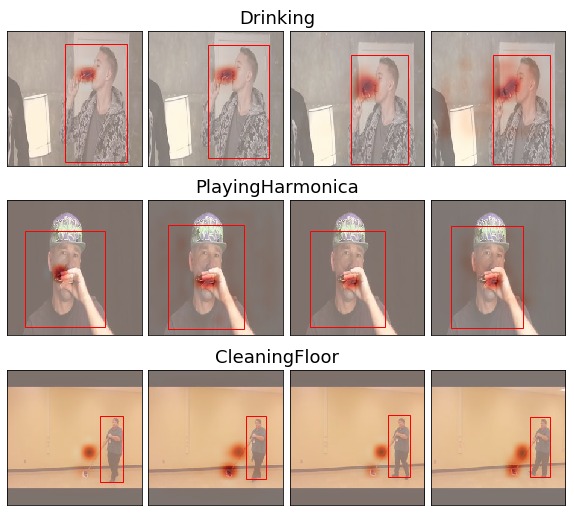
A graph network with attention, is able to learn human-object interactions in videos. The only supervision was where the actor is in the image. It was able to resolve the location of the manipulated object by itself, via a novel self-attention mechanism. The network itselved learned about the context, by a graph with two layers, each with two heads. The attention maps look very interesting!
Work with Fieke Hillerstrom (TNO), Michail Tsiousis (student), Peter van Putten (University of Leiden).