Cycle Consistency for Multi-Camera Matching
Matching objects across partially overlapping camera views is crucial in multi-camera systems and requires a view-invariant feature extraction network. But labelling in several cameras is labor-intensive. We rely on self-supervision, by making cycles of matches, from one camera to the next and back again. The cycles can be constructed in many ways. We diversify the training signal by varying the cycles.
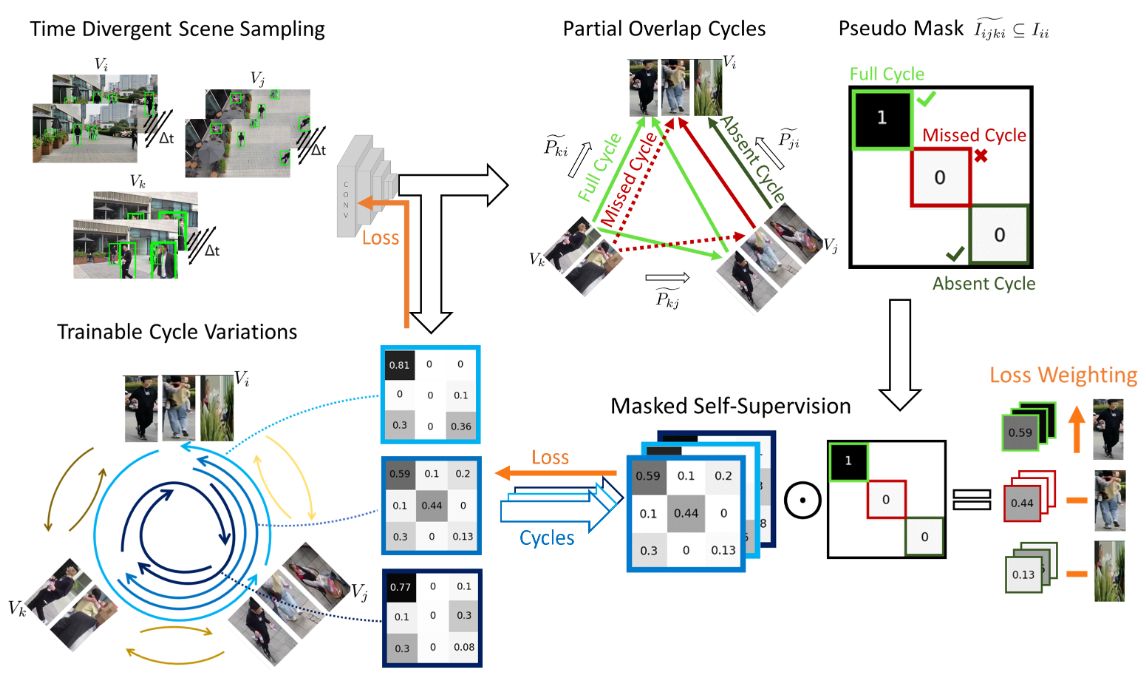
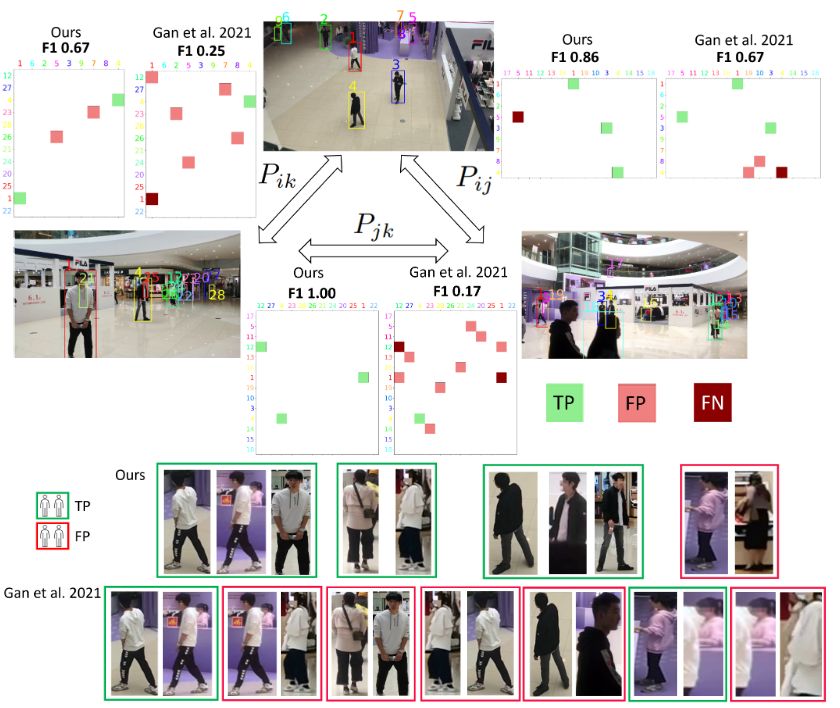
We achieve a 4.3 percentage point higher F1 score. Especially when there is limited overlap in camera views, the matching is improved.
Accepted at International Conference on Computer Vision Theory and Applications (VISAPP) 2025. See publications.