Improving DINO v2's Scene Understanding
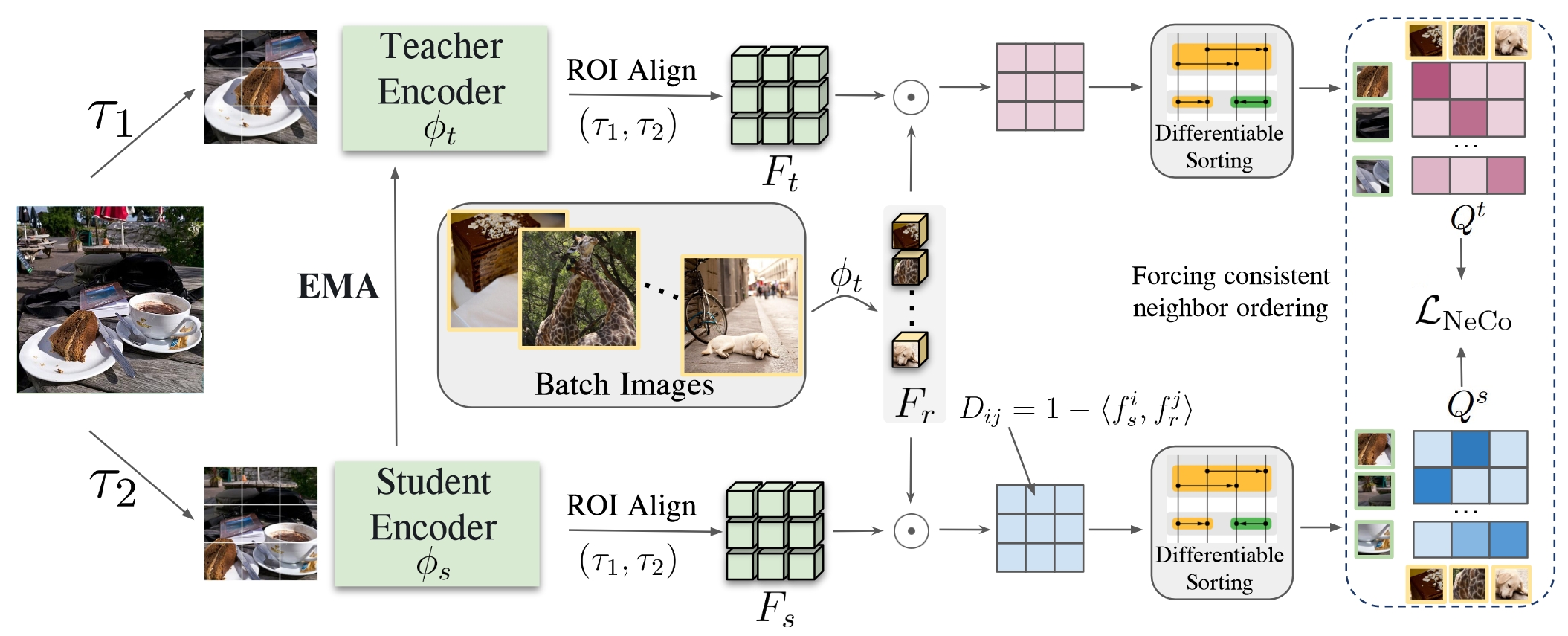
DINO v2 extracts strong features from an image at the patch level. However, it is not very consistent across images, e.g. it does not yield the same features for the tip of a finger across various people in different images. We aimed to improve this, by a self-supervised learning strategy.
Our strategy aims to improve the consistency, by enforcing that the patches in two views of the same image (i.e. different augmentations) follow the same ordering. This ordering proves to be a very strong learning signal: it is much stronger than just looking at the nearest neighbors only, or looking at clusters of patches in embedding space. Compared to contrastive approaches that only yield binary learning signals, i.e. “attract” and “repel”, this approach benefits from the more fine-grained learning signal of sorting spatially dense features relative to reference patches.
We call our method NeCo: Patch Neighbor Consistency.
We establish several new state-of-the-art results such as +5.5 % and +6% for non-parametric in-context semantic segmentation on ADE20k and Pascal VOC, +7.2% and +5.7% for linear segmentation evaluations on COCO-Things and -Stuff and improvements in the 3D understanding of multi-view consistency on SPair-71k, by more than 10%.

Its features are much more consistent across images and categories. E.g., it yields the same features for the tip of a finger across various people in different images.

Accepted at International Conference on Learning Representations (ICLR) 2025. See publications.