Reasoning about Affordances
If your robot needs to stand on an object to look on the other side, the object should be strong enough to hold the robot.
The SOTA methods do not take the physicality of the robot into account when selecting actions. We propose a dialogue that is able to reason about physicality and suitable objects for achieving the goal.
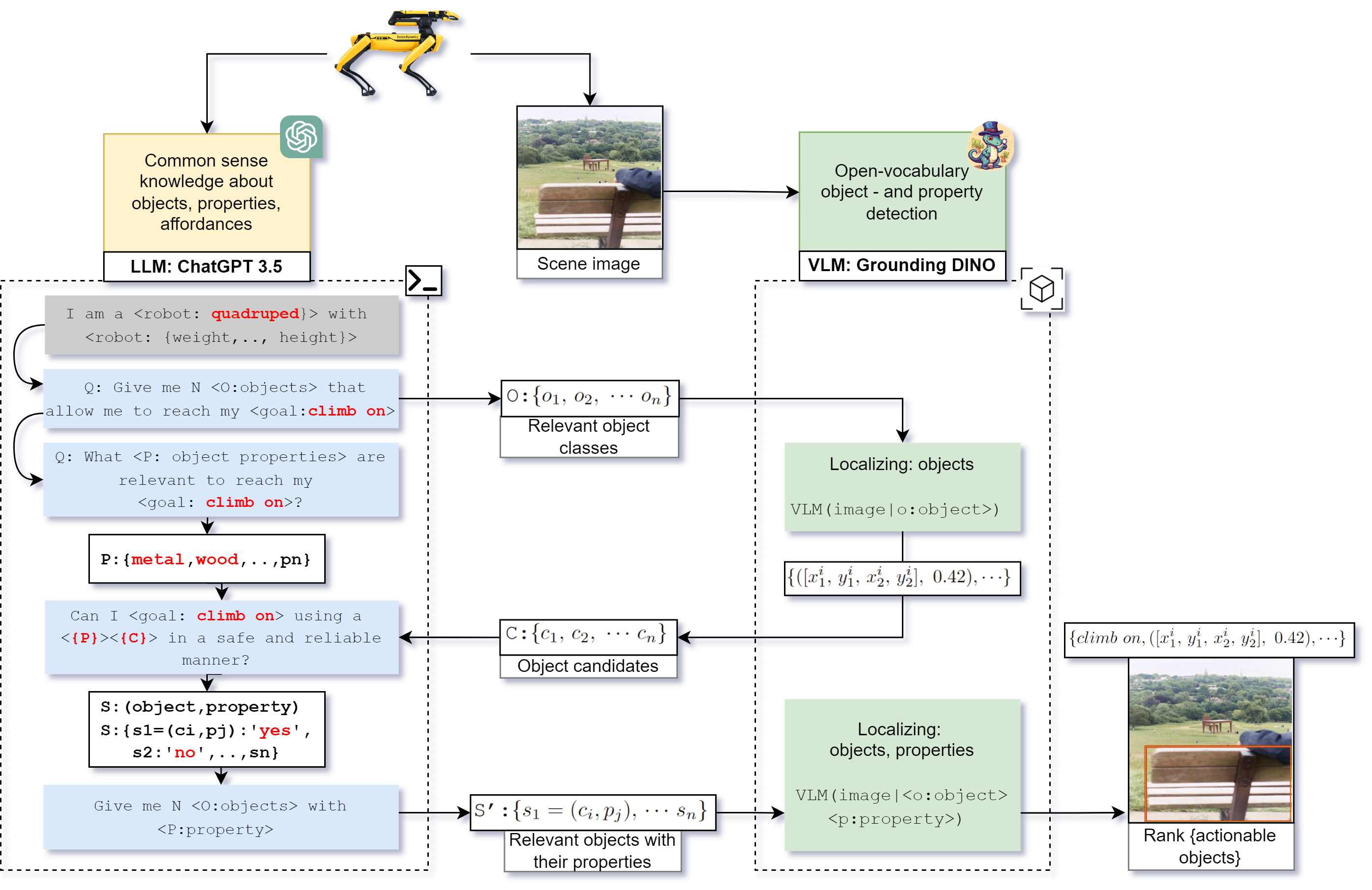
A large language model (LLM) is connected with a language-vision model (VLM). The LLM harnesses knowledge about the physical world, whereas the VLM is able to recognize objects.
We extended the VLM with a notion of physical properties of the objects. For instance, a box of carton is not strong enough, but a wooden box would be suitable.

Accepted at RSS 2024, Semantic Reasoning and Goal Understanding in Robotics.