Learning Objects without Forgetting
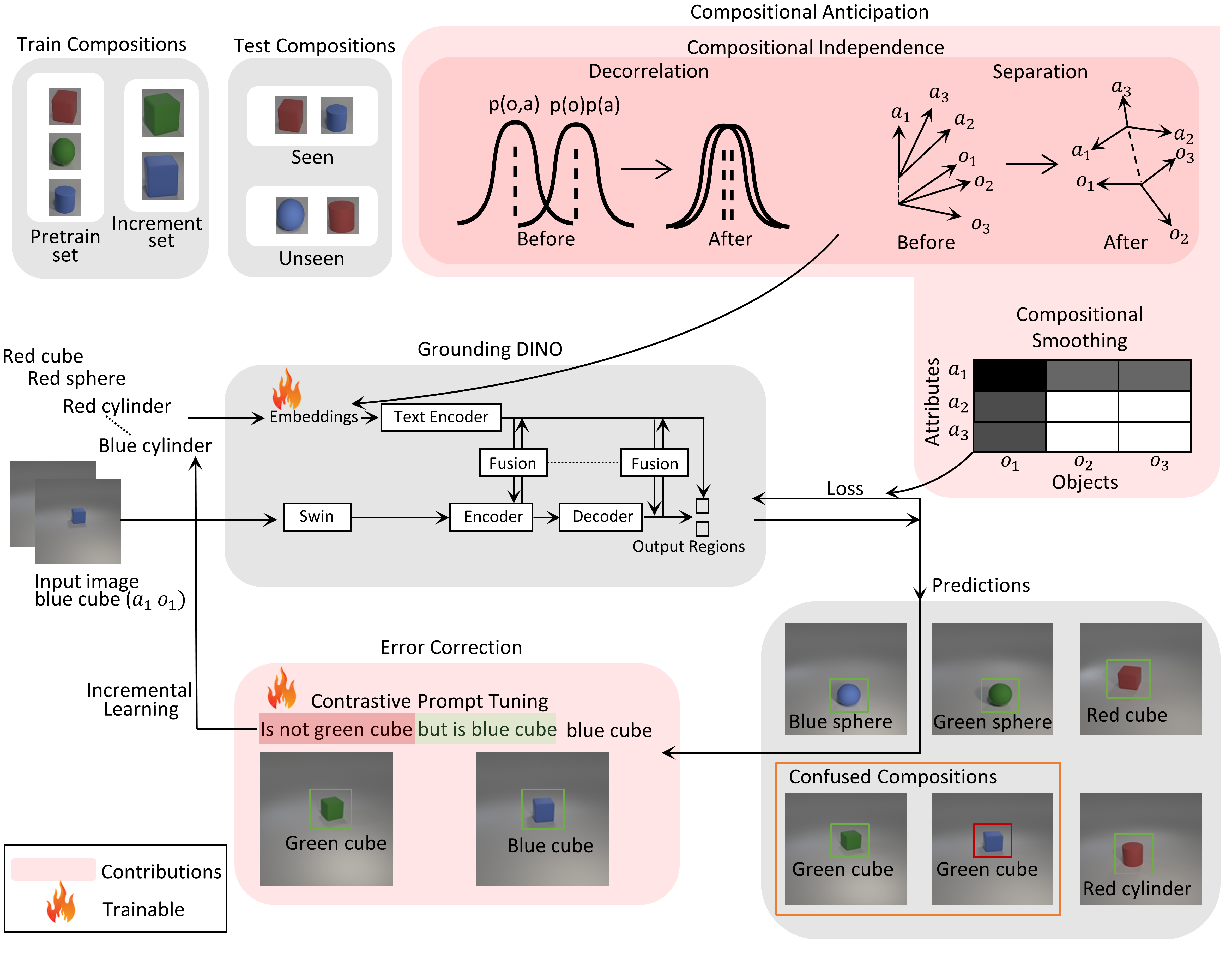
Our method recognizes and locates new objects, without forgetting the known objects. The latter in particular is a disadvantageous problem in practical applications: you want the model to really learn, and not just remember the most recently learned things and forget the rest.
We have improved a Vision-Language Model (VLM) by making the ‘register’ of known objects (LLM tokens) expandable. On top of that, we ensure that the objects differ from each other as much as possible, with some mathematical tricks.
Part of the FaRADAI project. Accepted at International Conference on Pattern Recognition, 2024.