Adaptive Prompt Tuning
The powerful CLIP model can be tuned for specialized tasks, by means of prompt tuning techniques, such as Context Optimization (CoOp) and Visual Prompt Tuning (VPT). These methods adds tokens to the prompt or model, but in a static way. We propose to dynamically refine the text prompt for the image at hand.
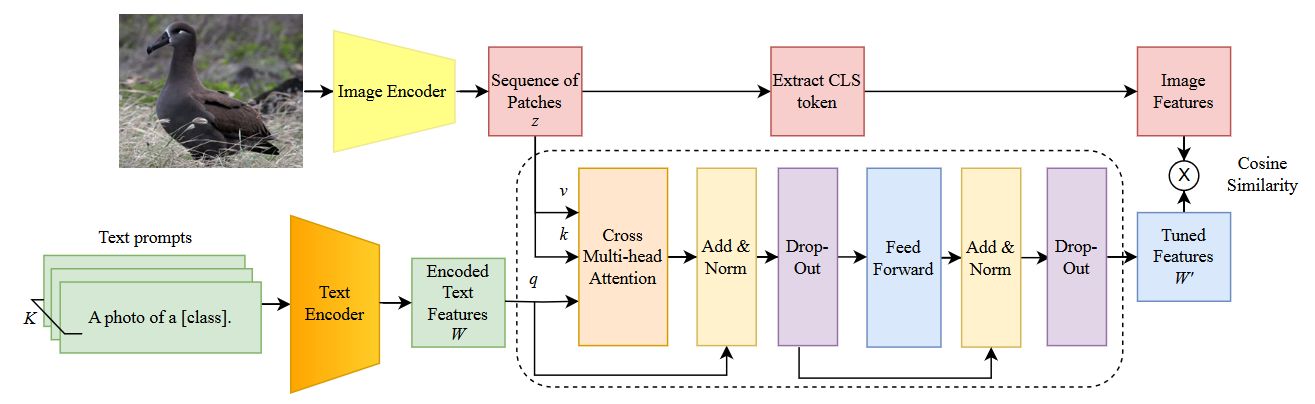
We devised a cross-attention mechanism. This enables an image-specific alignment of textual features with image patches extracted from the Vision Transformer, making the model more effective for datasets with high intra-class variance and low inter-class differences.
Accepted at International Conference on Computer Vision Theory and Applications (VISAPP) 2025. See publications.