Improved Localization of Objects in Context
Our paper got accepted by ICRA’s Pretraining for Robotics!
We recognize affordances in images. With this, a robot (e.g. SPOT) can find objects in images, that have a particular use for achieving its goal. For instance, opening a door by manipulating the handle.
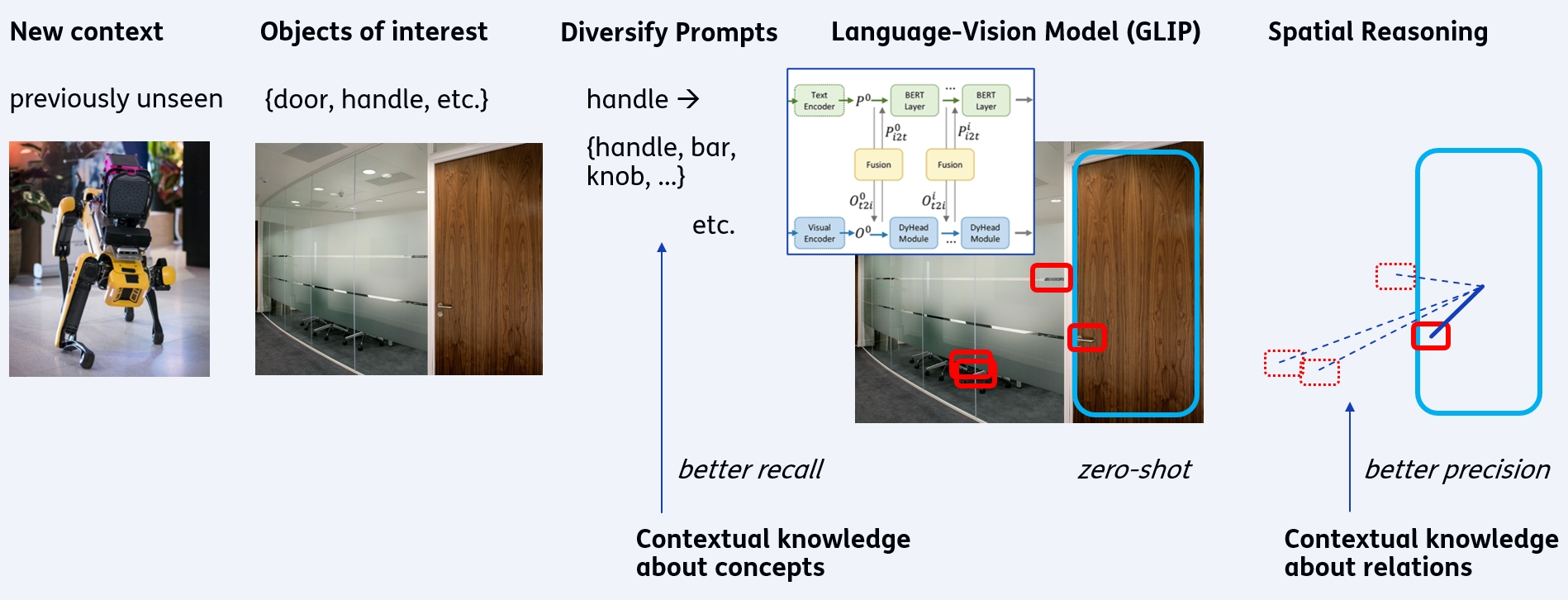
Our method finds such objects better, by leveraging prior knowledge. We improve GLIP, which is a language-vision model to find objects in images. We improve its inputs, by diversifying the textual prompts (a door can also be opened by a push bar instead of a handle). We also improve its outputs, by verification of the found objects, by checking their context (a handle should be close to the door).

A valuable asset for for robots searching for various objects without pretraining!
Paper at ICRA 2023 (see Publications). Funded by TNO Appl.AI program, SNOW project.