Maximum Separation between Classes
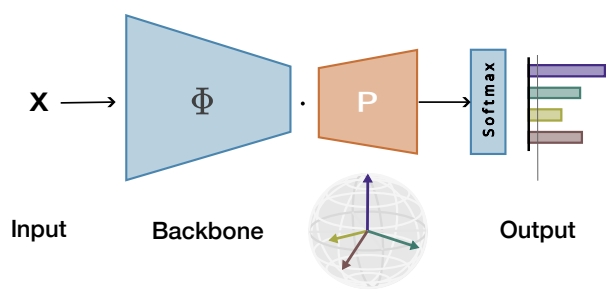
Maximizing the separation between classes constitutes a well-known inductive bias in machine learning and a pillar of many traditional algorithms. By default, deep networks are not equipped with this inductive bias and therefore many alternative solutions have been proposed through differential optimization. We propose a simple alternative: encoding maximum separation as an inductive bias in the network by adding one fixed matrix multiplication before computing the softmax activations.
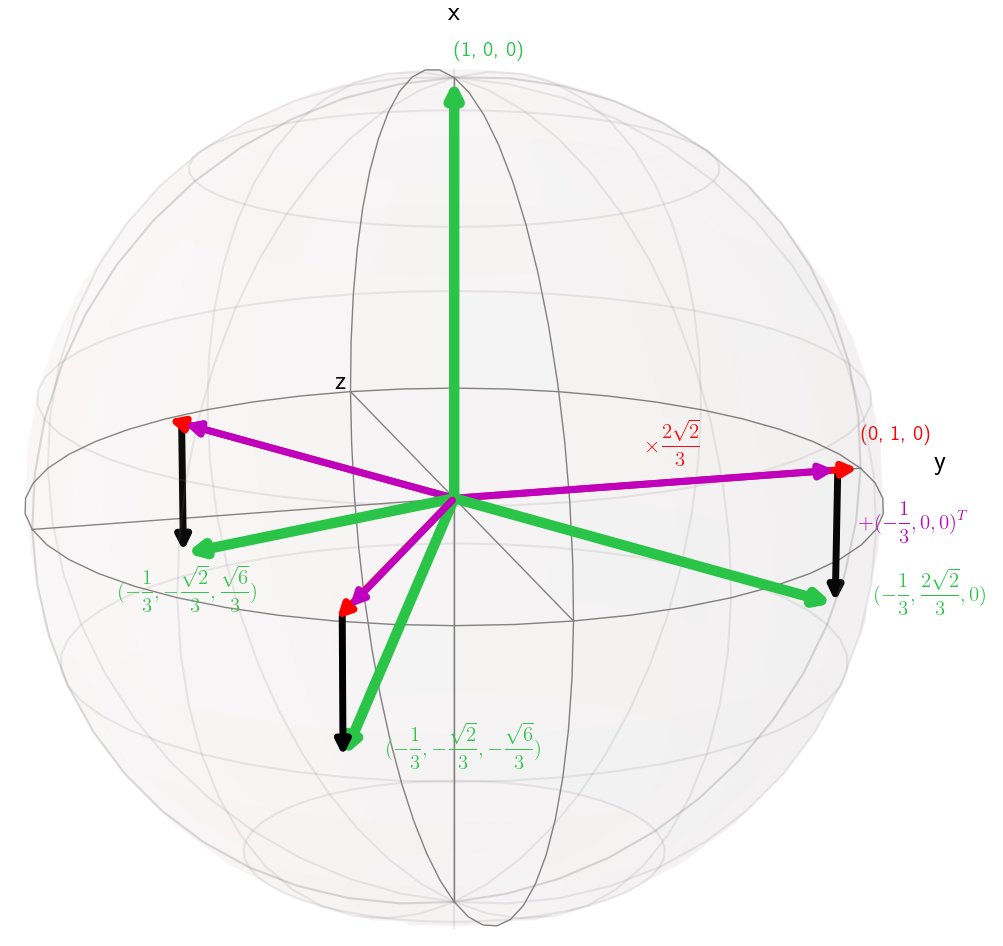
Despite its simple nature, this one matrix multiplication provides real impact. We show that our proposal directly boosts classification, long-tailed recognition, out-of-distribution detection, and open-set recognition, from CIFAR to ImageNet.
Work with Tejaswi Kasarla, Pascal Mettes, Max van Spengler, Elise van der Pol, Rita Cucchiara. Paper: https://arxiv.org/abs/2206.08704
