Visual Question Answering
Visual Question Answering (VQA) is a deep learning model that makes it possible to ask questions about an image in natural language. However, this often goes wrong in practice, especially with compound questions (“Is there a woman and a boy?”) and with questions that require understanding of the world (“a boy is a child”). Our method (Guided-VQA) extends VQA with such knowledge.
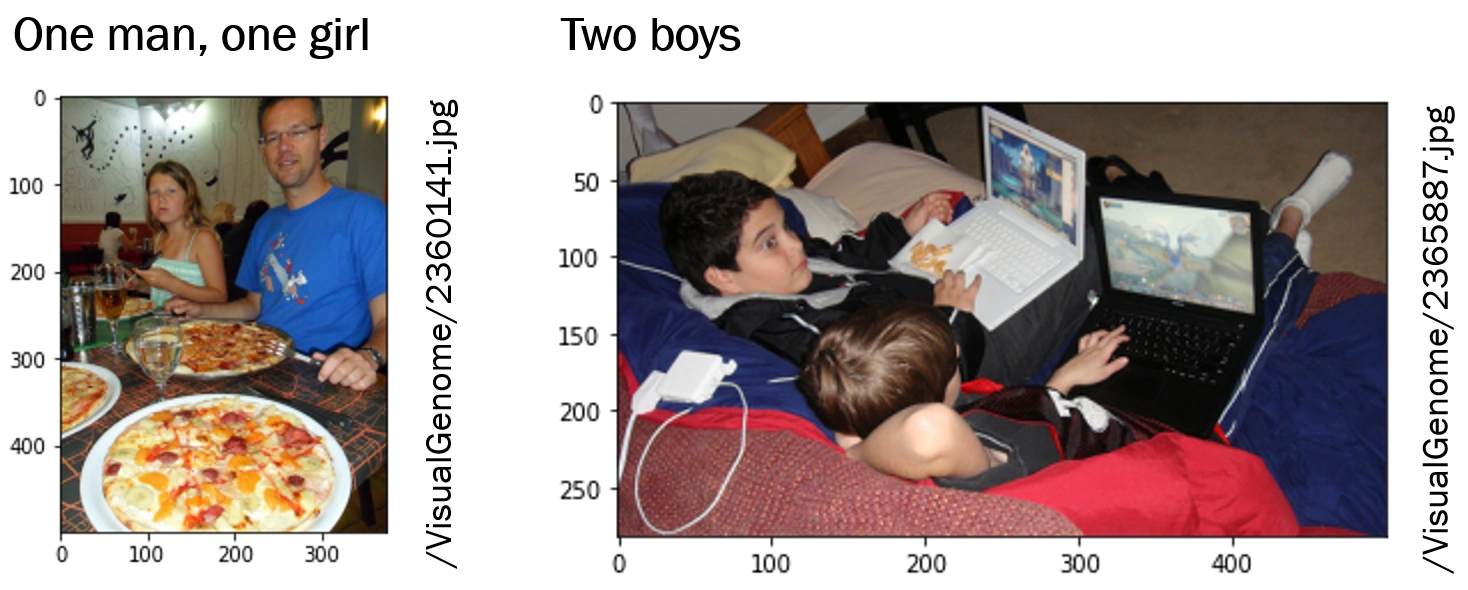
We have shown on the Visual Genome dataset that it leads to better answers. This technique allows us to search for objects for which we do not have an explicit detector, and combinations and relationships (“Is there a boy to the right of the woman?”).

Our idea is to decompose the compound queries, and to add common-sense to the resolving of such queries. We do so by an iterative, conditional refinement and contradiction removal. The refinement enables a coarse-to-fine questioning (leveraging taxonomic knowledge), whereas contradictions in the questioning are removed by logic. We coin our method ‘Guided-VQA’, because it incorporates guidance from external knowledge sources.
Published at International Conference on Image Analysis and Processing 2022.
(click on post to see more details)
We obtained good results on Visual Genome. On real-life images from different indoor family settings, our Guided-VQA achieved a mean average precision of 0.94 (VQA had 0.83). Especially on compound queries (e.g., one boy and two women) the results of Guided-VQA are better than as-is VQA. This is very relevant, because in a search & rescue scenario, the goal is to find the various family members (adults and children) in rooms of a personal house. What’s more: the answer’s confidences are much better interpretable, which is key to use them for further reasoning and/or human interpretation.
This research is part of Appl.AI SNOW (Context Awareness).