When Language Models Start to See
Can a language model help recognize images—even with only minimal visual training? Our recent research in Transactions on Machine Learning Research (TMLR journal) shows that it can.
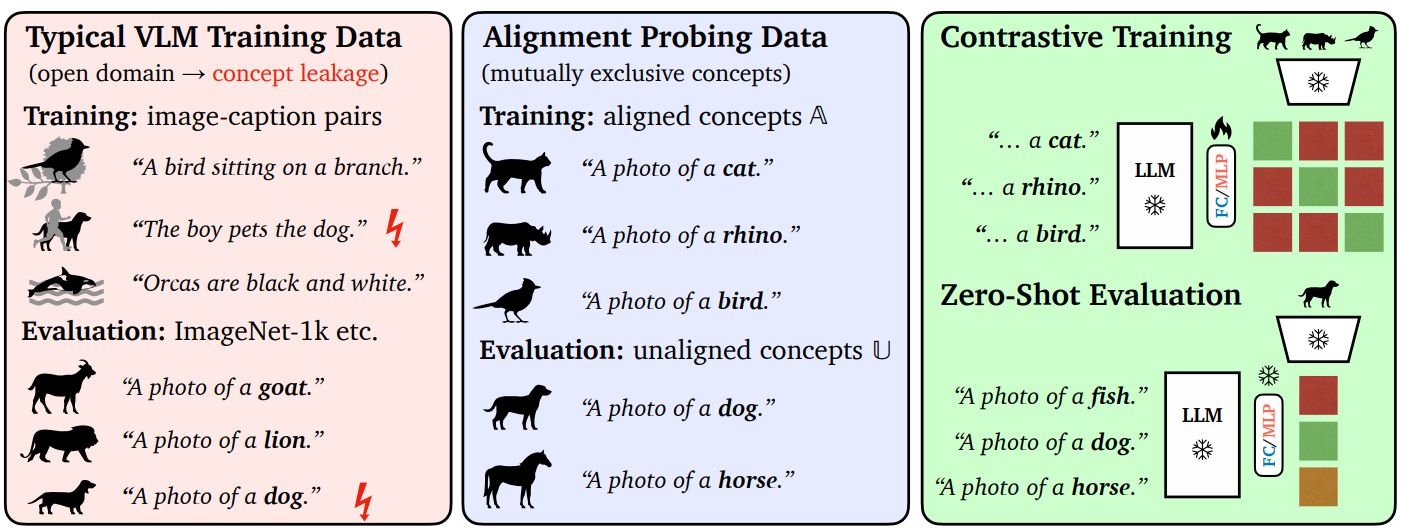
Although modern language models are trained purely on text, that text richly describes the visual world: objects, scenes, and how things relate. The question explored in this work is whether such models already contain visual structure that can be quickly unlocked with a small amount of image data.
The answer is yes. By adding a lightweight vision–language alignment step, researchers show that stronger language models require far less image–text training to perform well on visual recognition tasks. As language models improve, their representations align more naturally with visual concepts, making the final learning step remarkably efficient.
The technological breakthrough is clear: instead of training massive vision–language systems from scratch, we can reuse powerful language models and adapt them to vision with minimal extra supervision.
This points toward more data-efficient, scalable AI systems—and a future where language provides a surprisingly strong foundation for visual understanding.